

In this blog post, I’ll focus on new query processing capabilities in SingleStoreDB Self-Managed 6.8. The marquee query feature is just-in-time (JIT) compilation, which speeds up query runtimes on the first run of a query – now turned on by default. We have also improved performance of certain right and left outer joins and related operations, and Rollup and Cube. In addition, we add convenience features, including sub-select without an alias, and extended Oracle compatibility for date and time handling functions. Finally, new array functions for splitting strings and converting JSON data are added.
Other improvements in 6.8 are covered elsewhere. These include:
- secured HDFS pipelines
- improved pipelines performance
- LOAD DATA null column handling extensions
- information schema and management views enhancements
Now, let’s examine how just in time queries can work in a database.
Speeding up First Query Runtimes
SingleStore compiles queries to machine code, which allows us to get amazing performance, particularly when querying our in-memory rowstore tables. By spending a bit more time compiling than most databases – which interpret all queries, not compiling them – we get high performance during execution.
This works great for repetitive query workloads, such as real-time dashboards with a fixed set of queries and transactional applications. But our customers have been asking for better performance the first time a query is run, which is especially applicable for ad hoc queries – when slower performance can be especially noticeable.
In SingleStoreDB Self-Managed 6.7, we first documented a JIT feature for SQL queries, enabled by running ‘set interpretermode = interpret_first’. Under this setting, SingleStore starts out interpreting a query, compiles its operators in the background, then dynamically switches from interpretation to execution of compiled code for the query _as the query runs the first time. The interpret_first setting was classified as experimental in 6.7, and was off by default.
In 6.8, we’re pleased to say that interpret_first is now fully supported and is on by default. This setting can greatly improve the user’s experience running ad hoc queries, or when using any application that causes a lot of new SQL statements to be run, as when a user explores data through a graphical interface. The interpret_first setting can speed up the first run of a large and complex query – say, a query with more than seven joins – several times by reducing compile overhead, with no loss of performance on longer-running queries for their first run.
Rollup and Cube Performance Improvements
Cube and Rollup operator performance has been improved in SingleStoreDB Self-Managed 6.8 by pushing more work to the leaf nodes. In prior releases, Cube and Rollup were done on the aggregator, requiring more data to be gathered from the leaves to the aggregator, which can take more time. For example, consider the following query from the Cube and Rollup documentation:
SELECT state, product_id, SUM(quantity)
FROM sales
GROUP BY CUBE(state, product_id)
ORDER BY state, product_id;
The graphical query plan for this in 6.8, obtained using SingleStore Studio, is the following:
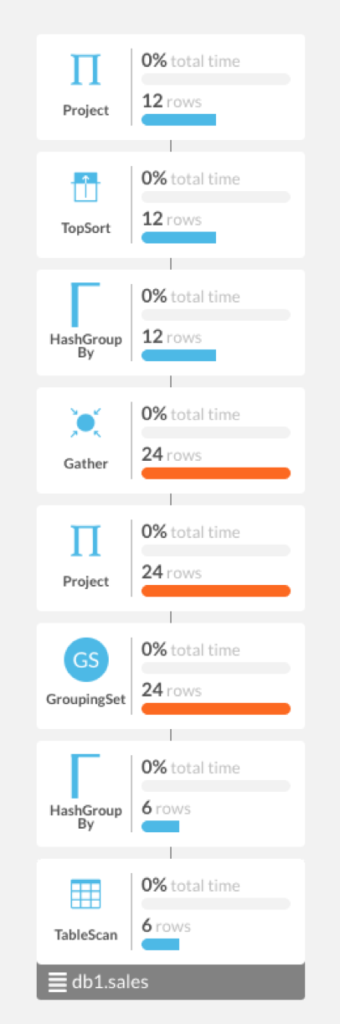
Notice the Grouping Set operator, third from the bottom, which is used for the Cube calculation. The Grouping Set operator is below the Gather operator, which means it is done on the leaves in this case.
This enhancement speeds up up several queries in the TPC-DS benchmark. In particular, query 67, which contains a large Rollup, improved by 5.5X compared with SingleStoreDB Self-Managed 6.7.
Right Semi/Anti/Outer Join Support
SingleStoreDB Self-Managed 6.8 introduces a new approach to executing certain outer-, semi-, and anti-joins. This does not add any new functional surface area to our SQL implementation; rather, it speeds up execution of some queries. A true right join operator is now supported, and certain kinds of left joins can be rewritten to right joins to enable them to run faster.
For example, consider two tables, S and L, where S is a small table and L is a large table. Suppose this query or subquery is encountered:
S left join L
This can be rewritten and executed as
L right join S
Here, the hash build side is for S. Then L is scanned and the L rows are used to probe the hash table for S. Since L is large and S is small, this is a good strategy for this query, since it results in a smaller hash table that can more easily fit in cache.
This enhancement can substantially speed up certain queries. For example, query 21 of the TPC-H benchmark speeded up about 4.3X using this approach from SingleStoreDB Self-Managed 6.7 to SingleStoreDB Self-Managed 6.8.
Subselect Without Alias
SingleStoreDB Self-Managed 6.8 now allows you to use a subquery without an alias (name) for it, when leaving off the alias will not be ambiguous. For example, you can now say this:
-- find average of the top 3 quantities
SELECT AVG(quantity)
FROM (SELECT * FROM sales ORDER BY quantity DESC LIMIT 3);
Rather than this:
SELECT AVG(quantity)
FROM (SELECT * FROM sales ORDER BY quantity DESC LIMIT 3) as x;
Resource Governor Extensions
SingleStoreDB Self-Managed 6.8 includes several extensions to the resource governor, which ensure that resources for more operations are governed under the desired pools. These extensions are:
- LOAD DATA operations now run in the pool for the current connection where the load operation is running.
- Stored procedures run in the resource pool of the current connection from where they are called.
- Query optimization work always runs in the pool of the current connection.
- Pipelines can be run under a pool you specify when you create the pipeline, using a new clause: [RESOURCE POOL pool_name].
New Built-In Functions
Two new built-in functions related to arrays are provided: SPLIT() and JSON_TO_ARRAY().
SPLIT()
The SPLIT() function has the following prototype:
split(s text [, separator text NOT NULL])returns array(text)
It splits a string into an array, using any amount of whitespace as a delimiter if no delimiter is specified. Or, if a delimiter is specified, it splits at that delimiter. For example, the query
SELECT array_length(split('a b c') :> array(text));
returns 3. Normally you would use SPLIT in a stored procedure (SP) or a user-defined function (UDF).
JSON_TO_ARRAY()
The JSON_TO_ARRAY() function takes a JSON array and returns a SingleStore array. If your applications use JSON data that contains arrays, you can use JSON_TO_ARRAY when processing it in SPs or UDFs. For example:
JSON_TO_ARRAY('[ "foo", 1,{"k1" : "v1", "k2" : "v2"} ]')
would produce a result array of JSON elements (we’ll call it r) of length 3 like this:
r[0] = "foo"
r[1] = 1
r[2] = '{"k1":"v1","k2":"v2"} '
Expression and Built-In Function Changes
A number of small changes have been made to new expression capabilities. First, in SingleStoreDB Self-Managed 6.7, we introduced a number of functions to make it easier to port Oracle applications and queries to SingleStore, and easier for experienced Oracle developers to use SingleStore. These include:
- NVL(), TO_DATE(), TO_TIMESTAMP(). TO_CHAR(), DECODE()
- REGEXP_REPLACE(), REGEXP_INSTR()
We’ve improved the compatibility of these functions as follows:
- Enable TO_DATE() to support format strings with time-related format options (“HH”, “SS”, etc.)
- Enable TO_DATE() to support the “DD” format option
- Enable TO_TIMESTAMP() to support “YY” and “FF” format options
- Enable TO_TIMESTAMP(), TO_DATE(), and TO_CHAR() to support the “D” format option
- Enable TO_TIMESTAMP() and TO_DATE() to support using different punctuation as a separator
- Enable TO_TIMESTAMP() and TO_DATE() to raise an error, instead of returning NULL, for certain error cases
- Enable TO_CHAR() to support “AM” and “PM”
- Modify how TO_TIMESTAMP() parses “12” when using the “HH” format option
In addition, we increased the precedence of || as concat (under sql_mode = ‘PIPES_AS_CONCAT’) to be compatible with MySQL and Postgres.
Summary
This post has covered the query processing extensions in SingleStoreDB Self-Managed 6.8. We hope you’ll especially enjoy the new JIT compilation feature that improves first-run query times by default. Try it for your ad hoc workloads. Please download SingleStoreDB Self-Managed 6.8 today!











