
John Sherwood, a senior engineer at SingleStore on the query optimizer team, presented at SingleStore’s Engineering Open House in our Seattle offices last month. He gave a technical introduction to the SingleStore database, including its support for in-memory rowstore tables and disk-backed columnstore tables, its SQL support and MySQL wire protocol compatibility, and how aggregator and leaf nodes interact to store data and answer queries simultaneously, scalably, and with low latencies. He also went into detail about code generation for queries and query execution. Following is a lightly edited transcript of John’s talk. – Ed.
This is a brief technical backgrounder on SingleStore, our features, our architecture, and so on. SingleStore: we exist. Very important first point. We have about 50 engineers scattered across our San Francisco and Seattle offices for the most part, but also a various set of offices across the rest of the country and the world.
With any company, and especially a database company, there is the question of why do we specifically exist? There’s absolutely no shortage of database products out there, as probably many of you could attest from your own companies.

Scale-out is of course a bare minimum these days, but the primary feature of SingleStore has traditionally been the in-memory rowstore which allows us to circumvent many of the issues that arise with disk-based databases. Along the way, we’ve added columnstore, with several of its own unique features, and of course you’re presented all this functionality through a MySQL wire protocol-compatible interface.

The rowstore requires that all the data can fit in main memory. By completely avoiding disk IO, we were able to make use of a variety of techniques to speed up the execution, with minimal principal latencies. The columnstore is able to leverage coding techniques that – with code generation and modern hardware – allow for incredibly fast scans.
The general market we find ourselves in is: companies who have large, shifting datasets, who are looking for very fast answers, ideally with minimal changes in latency, as well as those who have large historical data sets, who want very quick, efficient queries.
So, from 20,000 feet as mentioned, we scale out as well as up. At the very highest level, our cluster is made up of two kinds of nodes, leaves and aggregators. Leaves actually store data, while aggregators coordinate the data manipulation language (DML). There’s a single aggregator which we call the master aggregator – actually, in our codebase, we call it the Supreme Leader – which is actually responsible for coordinating the data definition language (DDL) and is the closest thing we have to Hadoop-style named namenode, et cetera that actually runs our cluster.

As mentioned, the interface at SingleStore is MySQL compatible with extensions and our basic idiom remains the same: database, tables, rows. The most immediate nuance is that our underlying system will automatically break a logical database into multiple physical partitions, each of which is visible on the actual leaf. While we are provisionally willing to shard data without regard to what the user gives us, we much prefer it if you actually use a shard key which allows us to set up convenient joins, et cetera, for actual exploration of data.
The aggregator then is responsible for formulating query plans, bridging out across leaves as necessary to service the DML. Of particular note is that the engine that we use is able to have leaves perform computations with the same full amount of functionality that the aggregator itself can perform, which allows us to perform many worthwhile optimizations across the cluster.

A quick, more visual example will better show what I’m talking about. Here we have an example cluster. We have a single master aggregator and three leaf nodes. A user has given us the very imaginatively named database “db” which we’re supposed to create. Immediately the aggregator’s job is to stripe this into multiple sub-databases, here shown as db_0 through db_2. In practice, we find that a database per physical core on the host works best, it allows parallelization and so on, but drawing out 48 of these boxes per would probably be a little bit much.
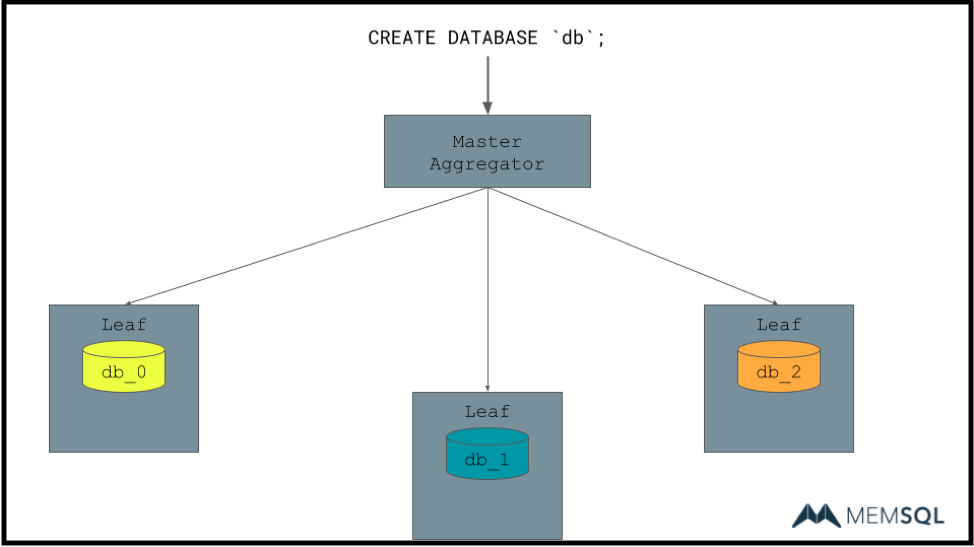
So beyond just creating the database, as mentioned, we have a job as a database to persist data. And as running on a single host does not get you very far in the modern world. And so, we have replication. We do this by database partition, replicating data from each leaf to a chosen replica.
So as you can see here, we’ve created a cluster such that there is no single point of failure. If a node goes down, such as this leaf mastering db_2, the other leaf that currently masters db_0 will be promoted, step up, and start new serving data.
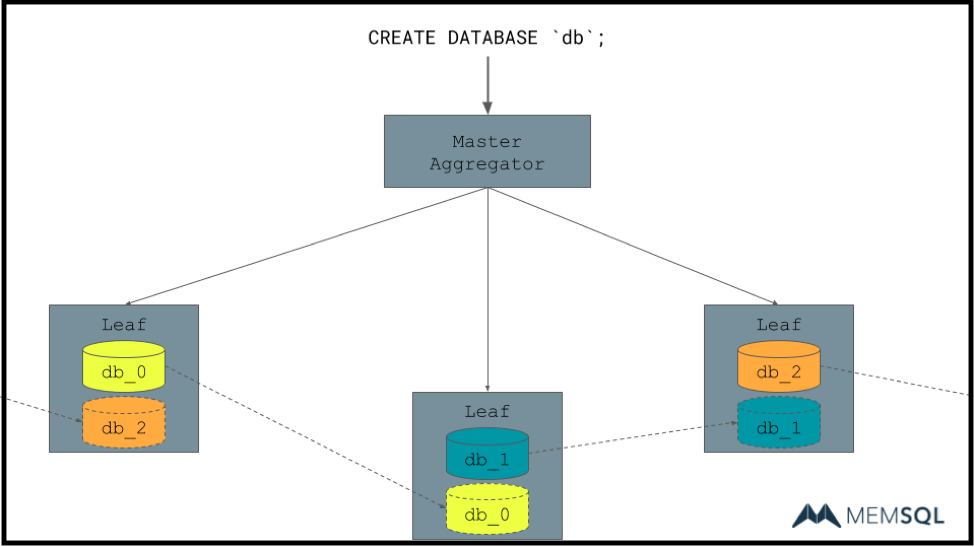
I’d also note that while I’m kind of hand waving a lot of things, all this does take place under a very heavy, two phase commit sort of thing. Such that we do handle failures properly, but for hopefully obvious reasons, I’m not going to go there.
So in a very basic example, let’s say a user is actually querying this cluster. As mentioned, they talked to the master aggregator that’s shown as the logical database, db as mentioned, which they treat as just any other data. The master aggregator in this case is going to have to fan out across all the leaves, query them individually and merge the results.
One thing that I will note here, is that I mentioned that we can actually perform computations on the leaves, in a way that allows us not to do so on the master. Here we have an order-by clause, which we actually push down to each leaf. Perhaps there was actually an index on A that we take advantage of.

Here the master aggregator will simply combine, merge, stream the results back. We can easily imagine that even for this trivial example, if each leaf is using its full storage for this table, the master aggregator (on homogenous hardware at least) will not be able to do a full quick sort, whatever you want to use, and actually sort all the data without spooling. And so even this trivial example shows how our distributed architecture allows faster speeds.
Before I move on, here’s an example of inserts. Here, as with point lookups and so on in the DML, we’re able to say the exact leaf that owns this row across its object.
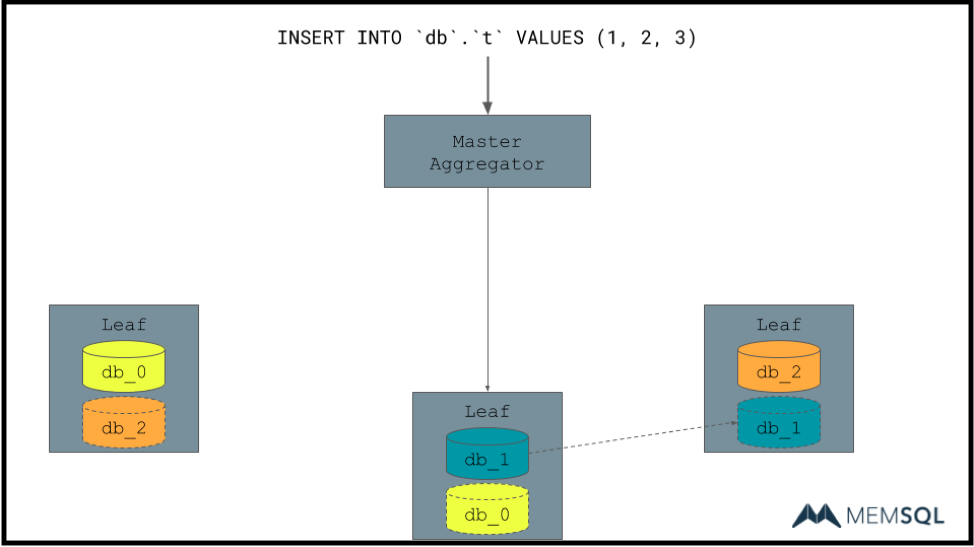
So here we talk to a single leaf end up transparently without the master aggregator necessarily knowing about it. Replicates that down to db_1’s replica on the other host. Allowing us to have durability, replication, all that good stuff.
Again, as a database, we are actually persisting everything in the data that has been entrusted to us. We kind of nuance between durability to the actual persistence of a single host versus replication across multiple hosts.
Like many databases, the strategy that we use for this is a streaming write-ahead-log which allows us to rephrase the problem from, “How do I stream transactions across the cluster?” to simply, “How do I actually replicate pages in an ordered log across multiple hosts?” As mentioned, this works at the database level, which means that there’s no actual concept of a schema, of the actual transactions themselves, or the row data. All that happens is that this storage layer is responsible for replicating these pages, the contents of which it is entirely agnostic to.

The other large feature of SingleStore is its code generation. Essentially the classic way for a database to work is injecting in what we would call in the C++ world, virtual functions. The idea that in the common case, you might have an operator comparing a field of a row to a constant value.

In a normal database you might inject an operator class that has a constant value, do a virtual function lookup to actually check that, and we go on with our lives. The nuance here is in a couple of ways this is suboptimal. First being that if we’re using a function pointer, a function call, we’re not in-line. And the second is simply that in making a function call, we’re having to dynamically look it up. Code generation on the other hand allows us to make those decisions beforehand, well before anything actually executes. This allows us both to make these basic optimizations where we could say, “this common case any engine would have – just optimize around it,” but also allows us to do very complex things outside of queries in a kind of precognitive way.
An impressive thing for most when they look through our code base is is just the amount of metadata we collect. We have huge amounts of data on various columns, on the tables and databases, and everything else. And at runtime if we were to attempt to read this, look at it, make decisions on it, we would be hopelessly slow. But instead, by using code generation, we’re able to make all the decisions up front, efficiently generate code and go on with our lives without having runtime costs. A huge lever for us is the fact that we use an LLVM toolchain underneath the hood, such that by generating IR – intermediate representation – LLVM, we can actually take advantage of the entire tool chain they’ve built up. In fact the same toolchain that we all love – or we would love if we actually used it here for our main code base – to use in our day to day lives. We get all those advantages: function inlining, loop unrolling vectorization, and so on.
And so between those two features we have the ability to build a next generation, amazing, streaming database.





