
Abstract
Many organizations today are looking for ways to run Machine Learning (ML) models in operational systems at scale. Data Scientists can now take models that they build in SageMaker and deploy them as user-defined functions within our general purpose, relational database. Read more about how you can accelerate the execution of your models against real time data. You can also find in-depth notebooks detailing how to implement this on GitHub.
Setting the Stage
AWS SageMaker has quickly become one of the most widely used data science platforms in the market today. Evidence suggests that even though there has been a proliferation of models in the enterprise, only 17% of companies have actually deployed a machine learning model into production. The following tutorial shares how we at SingleStore are helping our customers do just that.
Today, many enterprises are seeking to complete that machine learning lifecycle by deploying models in-database. There are many reasons why AI Engineers are taking this approach, as opposed to operationalizing their models using SageMaker:
- First, training and deploying models where the data lives means your models are always based on the entirety of your data, even the freshest records
- Keeping models in the same place as the data also reduces latency and cost (i.e., EC2) that the separation of the two may present
- In the case of real-time data, users can even run their models against every new live data point that is streamed into the database with amazing performance (while continuing to reference historical data)
Here at SingleStore, we are enabling AI developers to deploy models within our converged data platform. Our ability to ingest data in real-time from anywhere, perform sub-second petabyte-scale analytics with our Universal Storage engine and support for high concurrency makes us the perfect home for your models.
The next section details how SageMaker and Singlestore Helios, our cloud database-as-a-service offering, coexist to help accelerate your machine learning models.
Reference Architecture
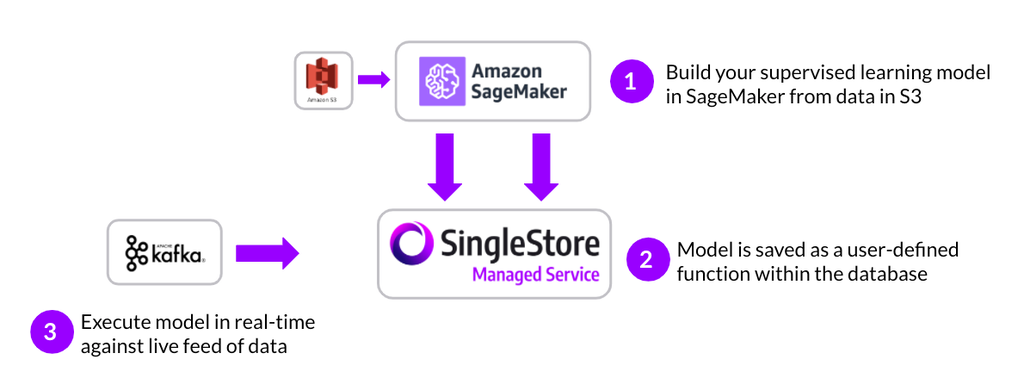
There are many different ways that machine learning engineers can use SageMaker and our Singlestore Helios together. The reference architecture below states just one approach, but these components can be variably interchanged based on your preferred architecture.
Below is an example of how SingleStore is able to easily leverage your existing data and modeling ecosystem of S3 and SageMaker working in-concert to make models run faster. In this architecture, models are built in SageMaker using data from S3. The models are then converted into UDFs using SingleStore’s “SageMaker to Python” library. At that point, the models live in the database and can be executed against real-time data streams coming from Kafka using native SQL. SingleStore also supports many other real-time and batch ingest methods, listed here.
Getting Started
To start leveraging AWS SageMaker and SingleStore, launch a Singlestore Helios Cluster here. This is our fully managed service in AWS that will allow you to try out all of the possibilities of SingleStore without the burden of infrastructure.
First, we will discuss how to collect your data and bring it into the platform. Then, we will train a machine learning model using that dataset. We will then deploy that model into the database and finally, use that model to score new data points that are coming from a real-time feed. Our entire example is run out of Jupyter notebooks, but you could also use our visual SQL client, SingleStore Studio, for many of the operations.
Data Collection
In this example, we will load the SageMaker sample bank churn data set into S3.
As demonstrated in the GitHub repository, we start this example by instantiating our AWS credentials and creating an S3 bucket:
**s3_input_train = sagemaker.s3_input(s3_data=f's3://{BUCKET} /train', content_type='csv')
**
Model Training
We will be using a gradient boosting framework for modeling. Gradient boosting is a method of supervised learning used for classification and regression problems. In this example, that means taking a set of variables and producing a prediction that represents a percentage likelihood of churn. Gradient boosting can also be used to predict categories rather than values. Today, we will use XGBoost, which is a library used for gradient boosting.
In order to train the model, we will call AWS SageMaker via Python. SageMaker allows us to select instance type, a number of instances, and a number of hyperparameters about the model when training it. These values will depend on the size of your dataset, the complexity of the model, etc.
**sess = sagemaker.Session(session)**
**xgb = sagemaker.estimator.Estimator(**
** CONTAINER,**
** ROLE,**
** train_instance_count=1,**
** train_instance_type='ml.m4.xlarge',**
** output_path=f's3://{BUCKET} /models',**
** sagemaker_session=sess)**
**xgb.set_hyperparameters(max_depth=5,eta=0.2,gamma=4,min_child_weight=6,subsample=0.8,silent=0,**
** objective='binary:logistic',num_round=100)**
**xgb.fit({'train': s3_input_train} )
**
Model Deployment
To deploy the model to SingleStore, we first establish the database connection using the SingleStore Python Connector. Next, we will use the SingleStore/SageMaker Python library to convert the XGBoost model into a user-defined function in the database. UDFs are how databases define a process to accept parameters, perform a calculation, and return a result.
**memsql_sagemaker.xgb_model_path_to_memsql(**
** 'predict_yes', xgb.model_data, memsql_conn, session,**
** feature_names=features, allow_overwrite=True)
**
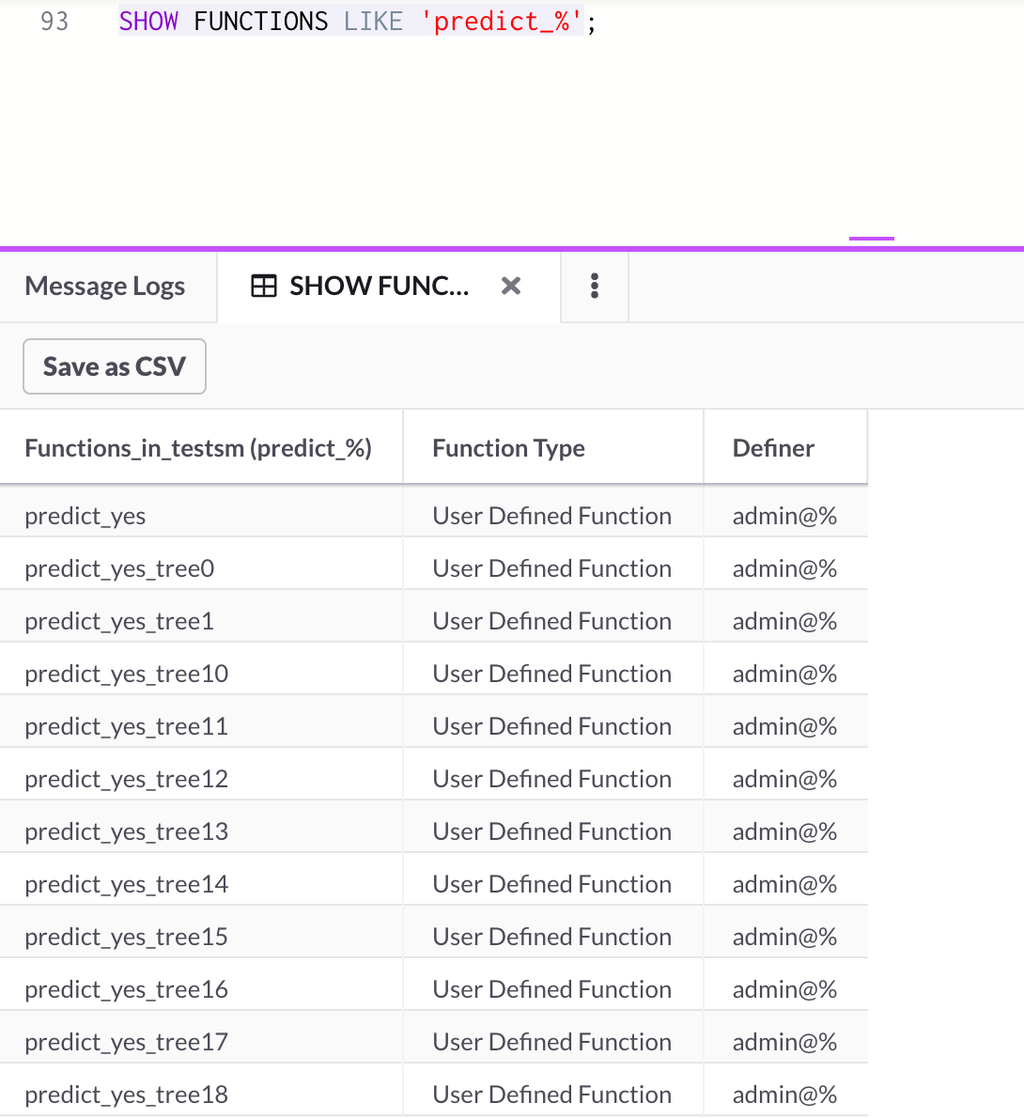
Once this step completes, we can run a simple SHOW FUNCTIONS command either from Python or from SingleStore Studio and we will see the SageMaker model deployed as a user-defined function in Singlestore Helios!
We can even quickly run our model against some sample rows in our dataset:
memsql_conn.query(f”SELECT predict_yes({‘,’.join(features)} ) as res FROM bank ORDER BY id LIMIT 10″)
Model Inferencing in Real-Time
The final step in the process of running our machine learning model in-database is to execute it against real-time data. In this example, we will use Kafka. Kafka is a great distributed event streaming platform, for which we have native connectivity in SingleStore using Pipelines.
Data consumed from Pipelines can land either directly into a table or into a stored procedure. In order to execute this model continually against live data, we will also need to use stored procedures. The procedure we define will run the model every time SingleStore consumes a new message from Kafka and land the prediction in a table directly.
**memsql_conn.query(**
** f'''**
** CREATE OR REPLACE PROCEDURE process_kafka_data(pipe query({", ".join([f"{f} DOUBLE NOT NULL" for f in ["id"] + list(all_data.columns)])} )) AS**
** BEGIN**
** INSERT INTO res(expected, predicted) **
** SELECT y_yes, predict_yes({", ".join(booster.feature_names)} )**
** FROM pipe;**
** END**
** '''** **)
**
Next, we will create the pipeline itself. As you will see, it is just a simple three lines of SQL to start consuming live data from Kafka. Pipelines enable us to ingest in a highly parallel fashion data in Kafka partitions.
**memsql_conn.query(**
** f'''**
** CREATE PIPELINE process_kafka_data **
** AS LOAD DATA KAFKA '{kafka_topic_endpoint} '**
** INTO PROCEDURE `process_kafka_data`**
** '''** **)**
**memsql_conn.query("START PIPELINE process_kafka_data")
**
As data starts to flow into SingleStore, we can make a simple query to the table directly to see our predictions:
**rows = memsql_conn.query("SELECT * FROM res LIMIT 5")**
**pd.DataFrame([dict(r) for r in rows]).head()
**
Summary
With Singlestore Helios and AWS SageMaker, we are able to both build and deploy supervised learning models against operational data. This enables our user base to be wise about their AWS investments, reduce latency in their data science environments, and have a unified store for all mission critical machine learning features.
You can try our Singlestore Helios today with $600 in Free Credits here.




