In part I of this blog, we demonstrated how to create parameterized queries (similar to Rockset's Query Lambdas) using SingleStore's Table-Valued Functions (TVF) and the Data API.

In part II, we’ll show you how to schedule these API calls to replicate Rockset’s scheduled query lambdas functionality via SingleStore’s Job Service.
Step 1. Setting up SingleStore
We’ll run through similar steps outlined in part I to set up a demo database. However, in this example, our TVF is going to query the users table to get the total user signups from the previous hour. This result will then be written to the hourly_user_signups table.
Create a SingleStore database
1CREATE DATABASE my_database;2USE my_database;
Create tables in SingleStore
1CREATE TABLE users (2 user_id INT PRIMARY KEY,3 username VARCHAR(255),4 email VARCHAR(255),5 created_at TIMESTAMP6);7 8CREATE TABLE hourly_user_signups (9 signup_datetime TIMESTAMP,10 total_signups INT11);
Insert sample data
1INSERT INTO users (user_id, username, email, created_at) VALUES2(1, 'john_doe', 'john@example.com', NOW()),3(2, 'jane_doe', 'jane@example.com', NOW());
Create a TVF to query the user table
1CREATE FUNCTION get_hourly_signups()2RETURNS TABLE AS RETURN3 SELECT DATE_TRUNC('hour', created_at) AS signup_datetime4 , COUNT(*) AS total_signups5 FROM users6 WHERE created_at >= DATE_TRUNC('hour', NOW()) - INTERVAL 1 HOUR7 AND created_at < DATE_TRUNC('hour', NOW());
Step 2. Create a SingleStore Notebook to perform your desired task
SingleStore Notebooks are hosted within SingleStore’s compute service, allowing you to execute both Python and SQL code.
For our use case, we’re going to create a notebook — which uses the TVF defined in step one — and takes the result set from that to update the hourly_user_signups table with the total signups from the previous hour. In step three, we’ll use the Job Service to run this notebook on a time-based schedule to repeatedly update the hourly_user_signups table with the most recent user signup counts.
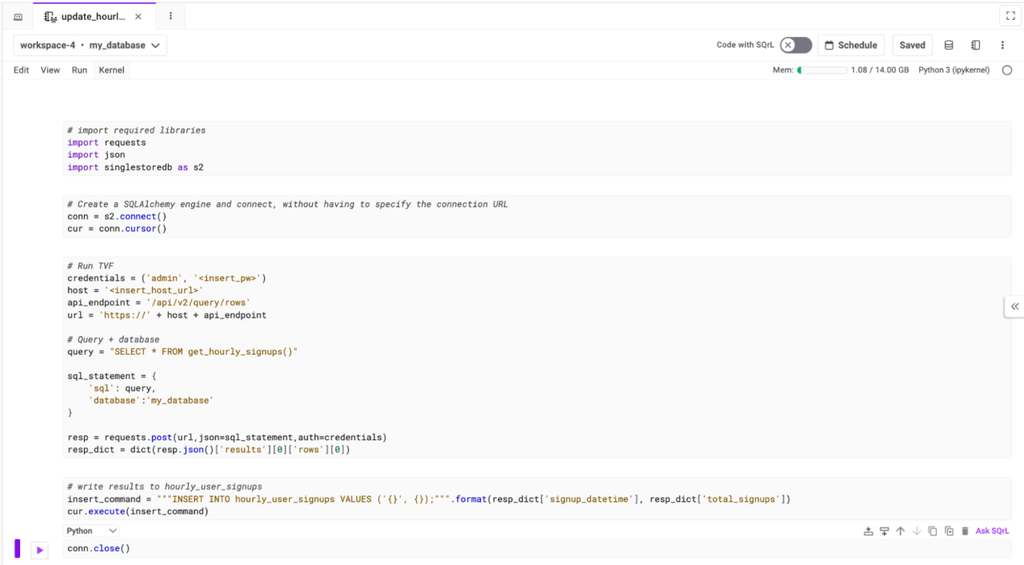
We’ll run through each of the code blocks in the notebook (appendix one contains a screenshot of the notebook). First we’ll import the required Python libraries and create a connection to SingleStore via our native Python connector.
1# import required libraries2import requests3import json4import singlestoredb as s25 6# Create a SQLAlchemy engine and connect, without having to specify the connection URL7conn = s2.connect()8cur = conn.cursor()
The next step is to execute the TVF via SingleStore’s Data API. This will return a Python dictionary containing the total signups from the users table in the previous hour.
1# Run TVF2credentials = ('admin', '<insert_pw>') 3host = '<insert_host_url>'4api_endpoint = '/api/v2/query/rows'5url = 'https://' + host + api_endpoint6 7# Query + database8query = "SELECT * FROM get_hourly_signups()"9 10sql_statement = {11 'sql': query,12 'database':'my_database'13}14 15resp = requests.post(url,json=sql_statement,auth=credentials)16resp_dict = dict(resp.json()['results'][0]['rows'][0])
Finally, we’ll insert the results from the data API call to update the hourly_users_signups table.
1# write results to hourly_user_signups2insert_command = """INSERT INTO hourly_user_signups VALUES ('{}', 3{});""".format(resp_dict['signup_datetime'], resp_dict['total_signups'])4cur.execute(insert_command)5 6conn.close()
We’ve used the data API along with a TVF here to follow along from part I of this blog. However, an easier way to complete this task would be to just use a SQL cell in the notebook and perform an INSERT INTO SELECT query.
Step 3. Use SingleStore’s Job Service to schedule running the notebook
Now that we have built the notebook to execute our task, we just need to schedule it to continuously update the hourly_user_signups table with the most recent aggregate data. This can be done via SingleStore’s Job Service which allows you to run your notebooks on a time-based schedule.
Jobs can be created in the SingleStore UI. On the left-hand panel, click the “Jobs” button, then click on “Schedule”. From there the following menu will pop up, and you can select:
- The notebook you want to schedule a job for
- The frequency at which you want to run the notebook
- The workspace and database to run the job against
In our example, we have selected the job to run once an hour at five minutes past the top of the hour. This allows the TVF to pull all user signups from the previous hour, inserting the aggregated result into the hourly_user_signups table.
.png?width=1024&disable=upscale&auto=webp)
In this blog, we have used SingleStore’s Job Service to create an aggregated view of the users table. Some other common use cases for this SingleStore Job Service functionality are:
- Data preparation and ML flows on your data stored in SingleStore
- Performing transforms and caching results in your SingleStore database
- Sending automated alerts
- Ingesting data from various sources into SingleStore
- Create and manage workspace groups and workspaces via the Management API
Part II of this blog demonstrates how you can schedule repetitive tasks to achieve similar functionality to Rockset’s Scheduled Query lambdas. It is important to note that any SQL or Python code can be executed within SingleStore notebooks — and users are not limited to using the Data API in conjunction with TVFs to create scheduled jobs.
If you’re looking for a Rockset alternative (or any database) and ready to start your migration, feel free to schedule time with a member of the SingleStore team here.
Appendix