

Autocomplete has become a standard feature in modern search-based applications, enhancing user experiences by predicting and suggesting words, phrases or queries as users type.
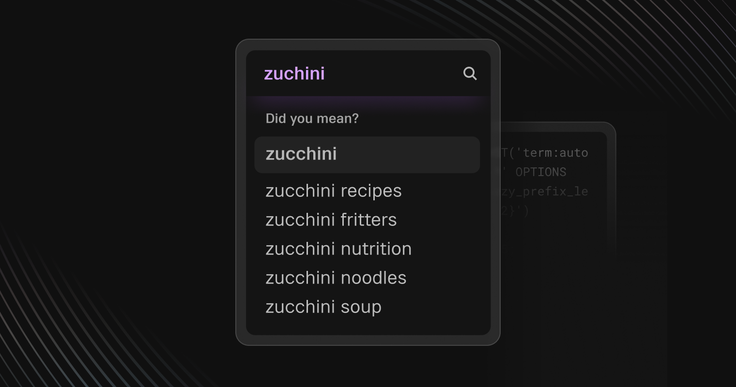
This functionality is widely implemented in search engines, code editors, messaging apps and other interactive platforms.
However, building an effective autocomplete system presents two key challenges:
- Typo tolerance. Ensuring the system can handle misspellings while still returning relevant suggestions.
- Real-time performance. Delivering suggestions with minimal latency, even when working with large datasets.
At the database layer, these challenges are typically addressed using a combination of:
- N-gram search for fast prefix-based matching
- Fuzzy search to accommodate misspellings and similar terms
- Ranking techniques like BM25 scoring to prioritize the most relevant results
In this article, we’ll walk through the implementation of a real-time, typo-tolerant autocomplete system using SingleStore, a modern HTAP database with Java Lucene-backed full-text search. We'll begin by explaining the key features of Full-Text Search that we’ll leverage, followed by a step-by-step breakdown of the autocomplete logic using SQL. Finally, we'll demonstrate how to integrate this feature into a Python application.
Full-text indexing, version 2
SingleStore has supported full-text search since 2018, but version 2 introduces major improvements with JLucene, a powerful open-source search library. Though JLucene is Java-based, SingleStore integrates it with SQL, making it easy to use without requiring deep Java expertise.
To build our autocomplete system, we will utilize the following key features:
N-gram search for fast prefix matching
The index automatically breaks down text into overlapping sequences of characters (n-grams) during indexing. This pre-processing enables quick prefix matching by comparing the n-gram tokens of the search term with those stored in the index, significantly reducing lookup time. For example, with a tri-gram full-text index, the word "apple" gets broken down into:
1app, ppl, ple
Fuzzy search for handling misspellings
Fuzzy search allows for minor spelling errors by specifying an edit distance (e.g., ~1). Edits include insertions, deletions, substitutions or transpositions of characters. When a fuzzy operator is appended to a term in the MATCH clause, SingleStore uses Damerau-Levenshtein distance to generate candidate matches within the allowed edit distance.
1SELECT term2FROM search_terms3WHERE MATCH(TABLE search_terms) AGAINST('term:autocmte~1' OPTIONS 4'{"fuzzy_prefix_length":2}')5LIMIT 5;
BM25 scoring for ranking relevance
BM25 ranks results based on term frequency and rarity, prioritizing the most relevant terms. It evaluates each document using term frequency, document length and inverse document frequency. SingleStore calculates a BM25 score for each match, ensuring that frequently occurring terms are ranked higher.
1SELECT term, BM25_GLOBAL(search_terms) AS score 2FROM search_terms 3WHERE MATCH(TABLE search_terms) AGAINST('term:autoc*' IN BOOLEAN MODE)4ORDER BY score DESC5LIMIT 10;
Building real-time autocomplete with typo tolerance
Now, let’s dive into a practical implementation of our real-time, typo-tolerant autocomplete system in SingleStore. We’ll start by defining the database schema, followed by the query patterns enabling prefix and fuzzy matching with BM25 scoring. Finally, we’ll demonstrate how to integrate these queries into a simple Flask application.
1. Database schema (optimized for N-gram + fuzzy search)
To efficiently handle partial inputs and typos, we’ll create a products table and configure its FULLTEXT index (version 2) with an n-gram tokenizer. This index breaks words into overlapping sequences, enabling rapid prefix matching.
1CREATE TABLE products (2 id INT AUTO_INCREMENT PRIMARY KEY,3 name VARCHAR(255),4 FULLTEXT USING VERSION 2 (name)5 INDEX_OPTIONS '{6 "analyzer": {7 "custom": {8 "tokenizer": {9 "n_gram": {10 "minGramSize": 2,11 "maxGramSize": 512 }13 },14 "token_filters": ["lower_case"]15 }16 }17 }'18);
Insert sample data:
1INSERT INTO products (name) VALUES2('iphone'),3('ipod'),4('ipad'),5('samsung'),6('nokia'),7('motorola'),8('pixel'),9('blackberry'),10('htc');11 12OPTIMIZE TABLE products FLUSH;13
This ensures the newly inserted data is picked up by the full-text index.
2. Queries and query patterns
Our autocomplete logic follows a two-step query strategy to return the best suggestions.
Step 1: Prefix (N-gram) search
1SELECT name, BM25(products, 'name:ip') AS score2FROM products3WHERE BM25(products, 'name:ip') > 04ORDER BY score DESC5LIMIT 10;
This query quickly retrieves partial matches based on the user's input.
Step 2: Fuzzy search (fallback for typos)
If fewer than five suggestions are found, and the user input is at least four characters, we perform a fuzzy match:
1SELECT name, BM25(products, 'name:ipod~1') AS score2FROM products3WHERE BM25(products, 'name:ipod~1') > 04ORDER BY score DESC5LIMIT 10;
This helps handle typos like "ipdo" instead of "ipod".
3. Application logic
A simple Flask API ties everything together:
setup_schema(). Creates the table, loads sample data and refreshes the index.get_autocomplete_suggestions(user_input). Runs prefix search first, then fuzzy search if needed.- Front-end integration. JavaScript calls the
/autocompleteendpoint and updates the UI with real-time suggestions.
You can find the full code snippets at this github repository.
Try SingleStore free
We built a real-time, typo-tolerant autocomplete system using SingleStore’s advanced full-text Search. By combining:
- N-gram search for prefix matching
- Fuzzy search for handling typos
- BM25 scoring for ranking results
We achieved an efficient and scalable solution. To productionize this solution, consider:
- Caching frequent queries with a SingleStore rowstore table to reduce latency
- Maintaining a typo-mapping table in SingleStore to improve accuracy
- Tuning BM25 parameters based on query analytics
SingleStore’s Universal Storage model and distributed execution provide a robust foundation for building high-performance search applications. With the right optimizations, this approach can power autocomplete experiences at scale.
Want to test it for yourself? Start your free SingleStore trial here!
Frequently Asked Questions










.jpg?width=24&disable=upscale&auto=webp)

