
Risk management is a critical task throughout the world of finance (and increasingly in other disciplines as well). It is a significant area of investment for IT teams across banks, investors, insurers, and other financial institutions. SingleStore has proven to be very well suited to support risk management and decisioning applications and analytics, as well as related areas such as fraud detection and wealth management.
In this case study we’ll show how one major financial services provider improved the performance and ease of development of their risk management decisioning by replacing Oracle with SingleStore and Kafka. We’ll also include some lessons learned from other, similar SingleStore implementations.
Starting with an Oracle-based Data Warehouse
At many of the financial services institutions we work with, Oracle is used as a database for transaction processing and, separately, as a data warehouse. In this architecture, an extract, transform, and load (ETL) process moves data between the operational database and the analytics data warehouse. Other ETL processes are also typically used to load additional data sources into the data warehouse.
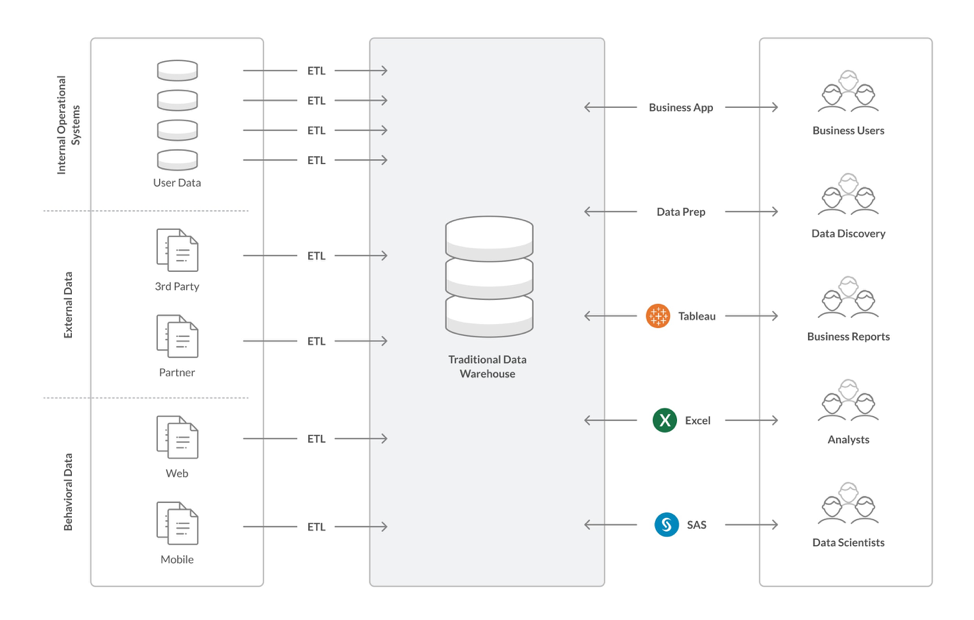
This architecture, while functional and scalable, is not ideal to meet the growing concurrency and performance expectations that risk management systems at financial institutions need to meet. SingleStore customers have seen a number of problems with these existing approaches:
- Stale data. Fresh transaction data that analytics users want is always a batch load (into the transaction database), a transaction processing cycle, and an ETL process away from showing up in the OLAP database.
- Variably aged data. Because there are different data sources with different processing schedules, comprehensive reporting and wide-ranging queries might have to wait until the slowest process has had a chance to come up to date.
- Operational complexity. Each ETL process is its own hassle, taking up operators’ time, and confusingly different from the others.
- Fragility. With multiple processes to juggle, a problem in one area causes problems for all the analytics users.
- Expense. The company has too many expensive contracts for databases and related technology and needs too many people with varied, specialized skills in operations.
What’s Needed in a Database Used for Risk Management
The requirements for a database used to support risk management are an intensification of the requirements for other data-related projects. A database used for risk management must power a data architecture that is:
- Fast. Under intense regulatory pressure, financial services companies are responsible for using all the data they have in their possession, now. Slow answers to questions are not acceptable.
- Up-to-date. The common cycle of running data through an OLTP database, an ETL process, and into an OLAP database / data warehouse results in stale data for analytics. This is increasingly unacceptable for risk management.
- Streaming-ready. There is increasing pressure for financial services institutions to stream incoming data into and through a database for immediate analytics availability. Today, Kafka provides the fast connections; databases must do their part to process data and move it along smartly.
- High concurrency. Top management wants analytics visibility across the entire company, while more and more people throughout the company see analytics as necessary for their daily work. This means that the database powering analytics must support large numbers of simultaneous users, with good responsiveness for all.
- Flexible. A risk management database may need to be hosted near to where its incoming data is, near to where its users are, or a combination. So it should be able to run in any public cloud, on premises, in a container or virtual machine, or in a blended environment to mix and match strengths, as needed to meet these requirements.
- Scalable. Ingest and processing requirements can grow rapidly in any part of the data transmission chain. A database must be scalable so as to provide arbitrarily large capacity wherever needed.
- SQL-enabled. Scores of popular business intelligence tools use SQL, and many users know how to compose ad hoc queries in SQL. Also, SQL operations have been optimized over a period of decades, meaning a SQL-capable database is more likely to meet performance requirements.
Two important capabilities for a risk management system highlight the importance of these valuable characteristics in the database driving the risk management system.
The first area is the need for pre-trade analysis. Traders want active feedback to their queries about the risk profile of a trade. They – and the organization – also need background analysis and alerting for trades that are unusually risky, or beyond a pre-set risk threshold.
Pre-trade analysis is computationally intense, but must not slow other work. (See “fast” and “high concurrency” above.) This analysis can be run as a trade is executed, or can be run as a precondition to executing the trade – and the trade can be flagged, or even held up, if the analysis is outside the organization’s guidelines.
What-if analysis – or its logical complement, exposure analysis – is a second area that is highly important for risk management. An exposure analysis answers questions such as, “What is our direct exposure to the Japanese yen?” That is, what part of our assets are denominated in yen?
It’s equally important to ask questions about indirect exposure – all the assets that are affected if the yen’s value moves strongly up or down. With this kind of analysis, an organization can avoid serious problems that might arise if its portfolios, as a group, drift too strongly into a given country, currency, commodity, and so on.
A what-if analysis addresses these same questions, but makes them more specific. “What if the yen goes up by 5% and the Chinese renmibi drops by 2%?” This is the kind of related set of currency movements that might occur if one country’s economy heats up and the other’s slows down.
These questions are computationally intense, require wide swaths of all the available data to answer – and must be able to run without slowing down other work, such as executing trades or powering real-time analytics dashboards. SingleStore characteristics such as speed, scalability, and support for a high degree of concurrency allow these risk management-specific needs to be addressed smoothly.
Improving Performance, Scale, and Ease of Development with SingleStore
Oracle, and other legacy relational databases, are relatively slow. They can only serve as an OLTP or OLAP database (not both in one); they do not support high concurrency or scale without significant added cost and complexity; and they require specialized hardware for acceleration. These legacy relational databases are also very expensive to license and operate compared to modern databases.
Oracle has worked to address many of these problems as their customers’ needs have changed. The scalability requirement for its single node architecture foundation can be partly met by scaling up — albeit to a massively expensive and hard to manage system, Exadata. Oracle also meets the SQL requirement, which gives it an advantage over NoSQL systems – but not over modern “NewSQL” databases like SingleStore.
After due consideration, the customer chose to move their analytics support from an Oracle data warehouse to SingleStore.
The Solution: A Dedicated Database for Analytics
To address the challenges with an Oracle-centric legacy architecture, one company we work with decided to move to a dedicated analytics database. This approach puts all the data that’s needed by the company on an ongoing basis into a single data store and makes it available for rapid, ongoing decision-making.
It also seeks to reduce the lag time from the original creation of a data item to its reflection in the data store. As part of this effort, all messaging between data sources and data stores is moved to a single messaging system, such as Apache Kafka. ETL processes are eliminated where possible, and standardized as loads into the messaging system where not.
This data store does a lot – but not everything. It very much supports ad hoc analytics queries, reporting, business intelligence tools, and operational uses of machine learning and AI.
What it doesn’t do is store all of the data for all of the time. There are cost, logistical, and speed advantages to not have all potentially relevant company data kept in this data store.
Data not needed for analytics is either deleted or – an increasingly common alternative – batch loaded into a data lake, often powered by Hadoop/HDFS, where it can be stored long-term, and also plumbed as needed by data scientists.
The data lake also serves a valuable governance function by allowing the organization to keep large amounts of raw or lightly processed data, enabling audits and far-reaching analytical efforts to access the widest possible range of data, without interfering with operational requirements.
SingleStore is well suited for use as a dedicated analytics database. SingleStore features fast ingest via its Pipeline features. It can also handle transactions on data coming in via the Pipeline – either directly, for lighter processing, or through the use of Pipelines to stored procedures for more complex work. Stored procedures add capability to the ingest and transformation process.
SingleStore can support data ingest, transactions, and queries, all running at the same time. Because it’s a distributed system, SingleStore can scale out to handle as much data ingest, transformational processing, and query traffic as needed.
A separate instance of SingleStore can also be used for the data lake, but that function is more often handled by Hadoop/HDFS or another system explicitly designed as a data lake.
Implementing SingleStore
The financial services company described above wanted to significantly improve their portfolio risk management capabilities, as well as other analytics capabilities. They also wanted to support both real-time use and research use of machine learning and AI.
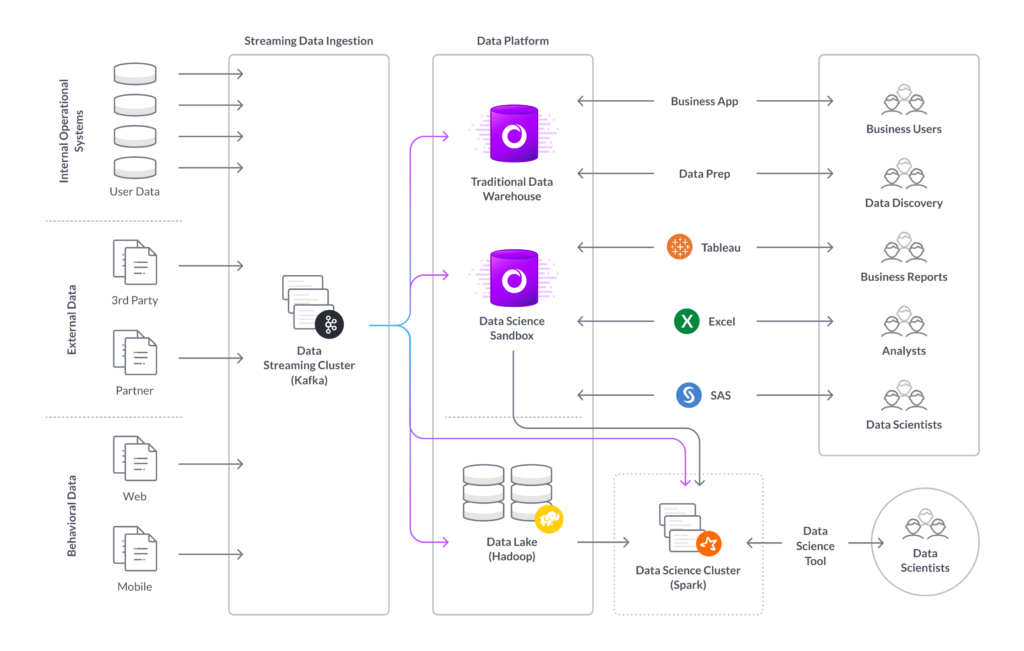
In support of these goals, the company implemented an increasingly common architecture based on three modern data tools:
- Messaging with Apache Kafka. The company standardized on Kafka for messaging, speeding data flows and simplifying operations.
- Analytics database consolidation to SingleStore. A single data store running on SingleStore was chosen as the engine and source of truth for analytics.
- Standalone data lake with Apache Hadoop. The data lake was taken out of the analytics flow and used to store a superset of the data.
As you can see, the core of the architecture became much simpler after the move to SingleStore as the dedicated analytics database. The architecture is made up of four silos.
Inputs
Each system, every external data source, and each internal source of behavioral data outputs to the same destination – a data streaming cluster running a Kafka-based streaming platform from Confluent.
Streaming Data Ingestion
The data streaming cluster receives all inputs and data to two different destinations:
- Analytics database. Most of the data goes to the analytics database.
- Data science sandbox. Some structured and semi-structured data goes to the data science sandbox.
- Hadoop/HDFS. All of the data is sent to Hadoop/HDFS for long-term storage.
Data Stores
SingleStore stores the analytics database and the data science sandbox. Hadoop/HDFS holds the data lake.
Queries
Queries come from several sources: ad hoc SQL queries; business apps; Tableau, the company’s main business intelligence tool; Microsoft Excel; SAS, the statistics tool; and data science tools.
Benefits of the Updated Data Platform
The customer who implemented risk management and other analytics, moving from ETL into Oracle to Kafka, SingleStore, and Hadoop, achieved a wide range of benefits.
They had begun with nightly batch loads for data, but needed to move to more frequent, intraday updates – without causing long waits or delays in analytics performance. For analytics, they needed sub-second response times for dozens of queries per second.
With SingleStore, the customer was able to load data in as soon as it became available. This led to better query performance, with query results that include the latest data. The customer has achieved greater performance, more uptime, and simpler application development. Risk managers have access to much more recent data.
Risk management users, analytics users overall, and data scientists share in a wide range of overall benefits, including:
- Reduction from Oracle licensing costs
- Reduced costs due to less need for servers, compute cores, and RAM
- Fresher data – new data available much faster
- Less coding for new apps
- Lower TCO
- Cloud connectivity and flexibility
- Reduction in operations costs
- Elimination of maintenance costs for outmoded batch apps
- More analytics users supported
- Faster analytics results
- Faster data science results
- New business opportunities
Why SingleStore for Risk Management?
SingleStore is fast – with the ability to scan up to one trillion rows per second. It’s a distributed SQL database, fully scalable. SingleStore supports streaming, in combination with messaging platforms such as Apache Kafka, and supports exactly-once guarantees. SingleStore supports high levels of concurrency and runs everywhere – on premises or in the cloud, in containers or virtual machines.
SingleStore customers often begin by moving some or all of their analytics to SingleStore for better responsiveness, greater concurrency, and reduced costs for the platform – including software licensing, hardware requirements, and operations expenses.
Customers then tend to find that SingleStore can take over more and more of the data pipeline. The combination of Kafka for messaging, SingleStore for data processing, Hadoop/HDFS as a data lake, and BYOBI (bring your own business intelligence, or BI, tools), can serve as a core architecture for a wide range of data analytics needs.
You can try SingleStore today for free. Or, contact us to speak with a technical professional who can describe how SingleStore can help you achieve your goals.





