
A benchmark asks a specific question, makes a guess about the expected result, and confirms or denies it with experiment. If it compares anything, it compares like to like and discloses enough details so that others can plausibly repeat it. If your benchmark does not do all of these things, it is not a benchmark.
Today’s question comes from one of our engineers, who was talking to a customer about new features in SingleStoreDB Self-Managed 4. We added support for SSL network encryption between clients and the cluster, and also between nodes in the cluster. The customer wanted to know how performance would be impacted.

The original question was about replication, but in SingleStore, replication happens over the same protocol as everything else. So we’ll generalize it a little to “What is the performance hit when SSL is turned on?” and then make it more specific, i.e. “what is the difference in sustained query throughput and latency between SSL on and SSL off for a given workload?”
Meet Herp and Derp

These are servers that used to be part of our continuous testing suite. Now they sit around doing benchmarks and party tricks. They are both Dell T610 mid-tower servers with two sockets, eight 2.5 GHz CPU cores, and 48GB of RAM. Not shown is burp, which is a 4-core box I scavenged out of a mess of parts at the local computer shop. We will set up the cluster with SingleStoreDB Self-Managed 4, one aggregator / traffic generator (burp), and two leaves (herp and derp) and high availability replication turned on between the leaves. I’m being a little cavalier about mixing the server and client workload, but it is unlikely that the bottleneck will be on the aggregator.
The dataset is a table with 200 million records. Each record has a geospatial point, a few numbers, and an index. They will be loaded with 8 write threads in batches of 10,000 each. Then we will start 16 read threads, which will continuously fire queries that select all points that lay inside randomly-generated geospatial polygons drawn on the surface of the Earth. The polygons will be sized such that about 80 points are retrieved from the index, filtering down to 40-50 points returned to the aggregator.
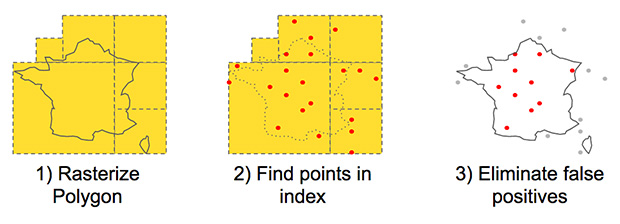
The read query load will be increased until the leaves hit 95% CPU utilization. Then we will measure sustained throughput and median latency. Finally, we will do it all over again with SSL and measure the difference.
Loading a batch of records into SingleStore involves three kinds of network connections: client to aggregator, aggregator to leaves, and (asynchronous) replication between leaves for high availability. All of these happen over the same protocol; replication clients simply connect like regular SQL clients then run a command that starts the firehose of data. The read queries require two network hops: client to aggregator, and aggregator to the leaves.
When SSL is on, we should expect higher latencies and higher demand for CPU. We should also see a reduction in overall throughput for the same number of threads. That is the bet, anyway. Let’s watch what happens.
Non-SSL Benchmark
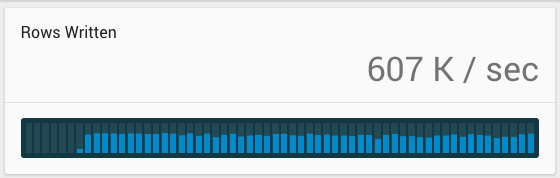
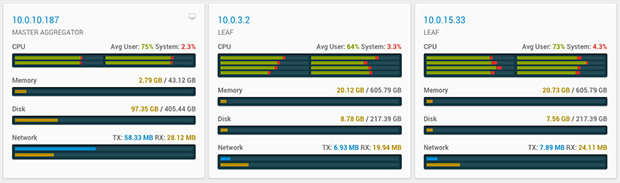
Loading data without SSL moved at a good clip; about 550,000 to 600,000 rows per second. As the table grew in size, this throughput dropped off gently. SingleStore in-memory tables are based on skiplists, which have log(N) insertion behavior. As N grows larger and larger, a little more work is needed per insert. Graphing insert volume over long periods of time would show a pretty catenary curve. CPU load was at decent levels during loading, but not at the saturation point.
$ time ./benchmark write-spatial
[...snip...]
200000000 total, 488849 per sec
**real 6m49.066s**
user 14m39.200s
sys 0m21.392s
(NB: though the Ops screenshots imply “600GB of Memory”, that is physical RAM plus swap.)
Reading was also straightforward. 16 threads was about right to pin the CPUs on the leaves, but left plenty of headroom on the aggregator/client machine.
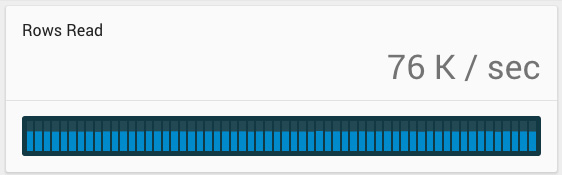
Read throughput on these geospatial queries was a steady 76,000 rows per second, or about 1,700 queries per second. One of the nice things about an in-memory database is no “warm up” or caching time on benchmarks; you reach cruising altitude immediately. The median latency was 7.7 milliseconds, p95 was 14 msec. Not bad for a pile of junk computers.
SSL Benchmark
I dropped the database, then configured SSL certificates so that all intra-cluster communication was secured, and restarted. Just to check whether SSL was on, I connected with a MySQL client and the certificate I’d generated.
$ mysql -uroot -h burp --ssl-ca=ca-cert.pem -e "show variables like '%ssl%'"
+---------------+--------------------------+
| Variable_name | Value |
+---------------+--------------------------+
| have_openssl | ON |
| have_ssl | ON |
| ssl_ca | ../certs/ca-cert.pem |
| ssl_capath | |
| ssl_cert | ../certs/server-cert.pem |
| ssl_cipher | |
| ssl_key | ../certs/server-key.pem |
+---------------+--------------------------+
Now, on to the benchmark. I modified the benchmark script, which uses the singlestore.common Python convenience library, to connect via SSL.
pool = connection_pool.ConnectionPool()
db = pool.connect('127.0.0.1', '3306', 'root', '', '',{'ssl': '../certs/ca-cert.pem'} )
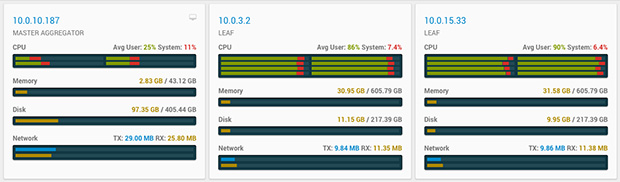
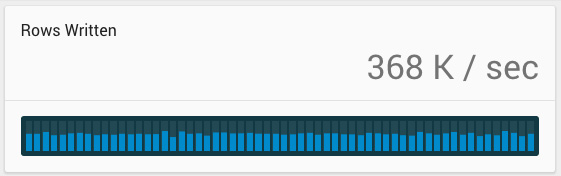
And off we go! Writes initially clocked in at 425,000 rows per second, trending down to 350K or so by the end. The aggregator’s CPU was higher with SSL on, since it was handling three separate encrypted links (client to aggregator, aggregator to client, aggregator to leaves). Note that in both write tests, we did not achieve CPU saturation on the leaves, so these are lower bounds.

$ time ./benchmark write-spatial
[...snip...]
200000000 total, 387458 per sec
**real 8m36.118s**
user 14m29.685s
sys 0m14.852s
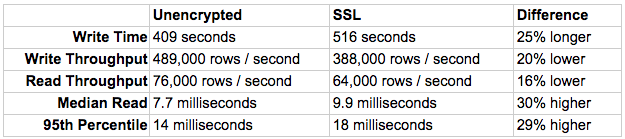
The overall insert time for 200 million rows was 8:36, compared to 6:49 for the non-SSL config. Overall, 25% less write throughput. Now, on to reads.
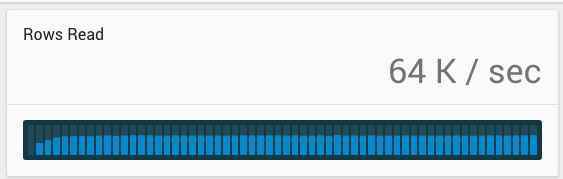
Read query throughput clocked in at 64,000 rows and just under 1,500 queries per second under SSL. Compared to the 76K from the non-SSL config, that’s a 16% drop in read throughput. Median latency was 10 msec with a p95 of 18 msec. Both reads tests reached full CPU saturation.
And that is a decent benchmark. We asked a specific question and answered it with an experiment, comparing the same metrics against one and only one difference. Even though I lost the bet that the aggregator + client load would not bottleneck burp, the skew was not too large. Lastly, there is enough detail that you can repeat the test and be reasonably sure you will get similar results.
But do not generalize everything you read. You cannot flatly say that “SSL is a 16% latency hit on SingleStore”. Larger polygons would probably give different results. Other kinds of queries, like distributed joins, would perform extra communication between leaves. We can make any number of guesses at what the result may be, but only a good benchmark can answer it.
Try this at home
The script I used is up on Github (it is ugly; be kind). Below is the schema, some sample data, and queries.
CREATE TABLE terrain_points (
location geographypoint DEFAULT 'Point(0 0)',
elevation int(10) unsigned NOT NULL,
ent_id int(10) unsigned NOT NULL,
time_sec int(10) unsigned NOT NULL,
SHARD KEY location (location, ent_id, time_sec)
);
memsql> select * from perf.terrain_points limit 5;
+----------------------------------+-----------+----------+------------+
| location | elevation | ent_id | time_sec |
+----------------------------------+-----------+----------+------------+
| POINT(-89.00991728 7.95282675) | 28822 | 20333901 | 1432681250 |
| POINT(177.53195551 -32.35287545) | 64465 | 25248309 | 1432681250 |
| POINT(-150.17150895 10.02000130) | 43688 | 66406185 | 1432681250 |
| POINT(77.94888837 19.91037133) | 57739 | 26693242 | 1432681250 |
| POINT(-125.70522605 45.54260644) | 41195 | 24162850 | 1432681250 |
+----------------------------------+-----------+----------+------------+
5 rows in set (0.02 sec)
memsql> SELECT * FROM perf.terrain_points with (index=location, resolution=6) WHERE geography_intersects(location, 'POLYGON((166.07059780 -13.90684205, 166.06868866 -13.90694224, 166.02333020 -13.93129089, 166.01865319 -13.99425334, 166.02876188 -14.00779541, 166.03506682 -14.01331439, 166.03979604 -14.01657349, 166.10317282 -14.01829710, 166.10531622 -14.01706579, 166.11815640 -14.00676434, 166.11893834 -14.00592391, 166.13045244 -13.98737615, 166.07059780 -13.90684205))');
+----------------------------------+-----------+----------+------------+
| location | elevation | ent_id | time_sec |
+----------------------------------+-----------+----------+------------+
| POINT(166.09984350 -14.00177767) | 36606 | 22886130 | 1432768116 |
| POINT(166.06090626 -13.95221591) | 70244 | 19588890 | 1432767950 |
| POINT(166.11221990 -13.97041329) | 32433 | 70087923 | 1432768053 |
[...snip...]
| POINT(166.05442264 -13.96318868) | 84910 | 74432027 | 1432767899 |
+----------------------------------+-----------+----------+------------+
38 rows in set (0.01 sec)
You can download SingleStore Community Edition for free and try this for yourself.





