

In Short:
A range of assumptions led to a boom in NoSQL solutions, but in the end, SQL and relational models find their way back as a critical part of data management.
In the End We Seek Structure. Why SQL and relational models are back as a critical part of data management – Click to Tweet
Background
By the mid 2000s, 10 years into the Netscape-inspired mainstream Internet, webscale workloads were pushing the limits of conventional databases. Traditional solutions could not keep up with a myriad of Internet users simultaneously accessing the same application and database.
At the time, many websites used relational databases like MySQL, SQL Server from Microsoft, or Oracle. Each of these databases relied on a relational model using SQL, the Structured Query Language, which emerged nearly 40 years ago and remains the lingua franca of data management.
Genesis of NoSQL
Scaling solutions is hard, and in particular scaling a relational, SQL database proved particularly challenging, in part leading to the emergence of the NoSQL movement.
FIGURE 1: Interest in NoSQL 2009 – 2015 Source: Google Trends
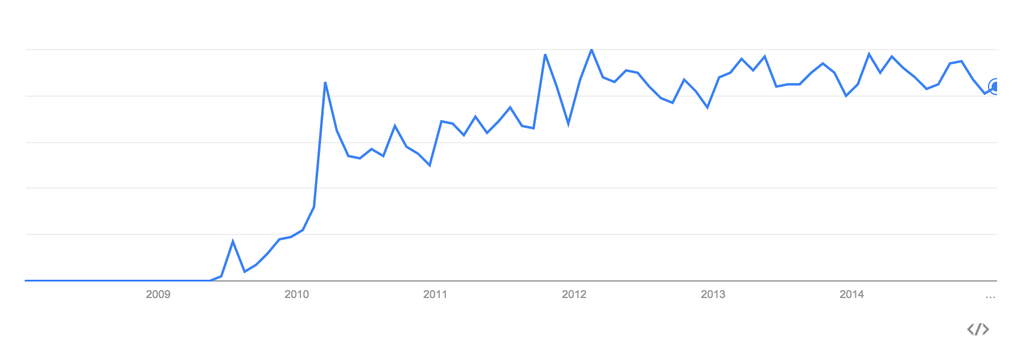
While there are numerous reasons to explain this interest graph, a few include prior solutions being
- hard to scale
- hard to achieve new performance needs
- hard to build
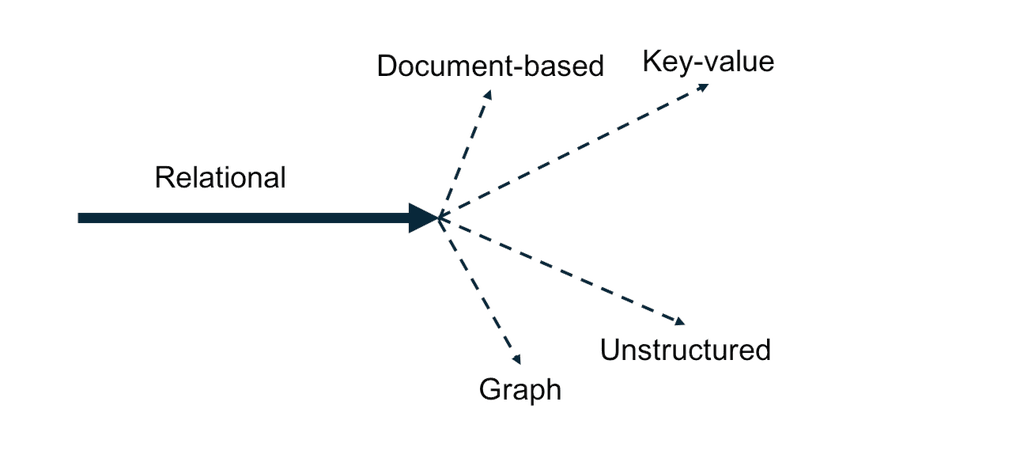
An Explosion of Database Options
As developers sought alternatives, an explosion of database options emerged.
- Document Datastores
Enabled scheme-less design which made a building new applications a breeze, but running concurrent reads and writes a significant challenge
- Document Datastores
- Key-value Stores
Offered simple lookups and scale based on an eventual consistency model suitable to some, but not all, workloads
- Key-value Stores
- Unstructured File Systems
Delivered nearly infinite distributed storage making it easy to store everything, but nearly impossible to quickly make use of it
- Unstructured File Systems
- Graph Databases
Provided a superior data model for graph-specific datasets but not enough to cover a full spectrum of data management
- Graph Databases
FIGURE 2: An Explosion of Database Options
Some SQL With Your NoSQL
As reality hit, many approaches edged back towards a relational and SQL focused model.
Document datastore companies incorporated 3rd party storage engines to solve some of the most complex parts of operational, and relational, databases like multi-version concurrency control and record-level locking, as opposed to database locking.
Key-value companies developed entirely new custom query languages that while kind of like SQL, are not. A query language per datastore became the norm.
Unstructured file systems, holding troves of untapped data, quickly spurred an entire market of SQL on Hadoop solutions so customers could make use of everything they had been storing.
And some smaller graph database companies merged with larger NoSQL companies perhaps because the graph-only market did not represent a large enough independent opportunity.
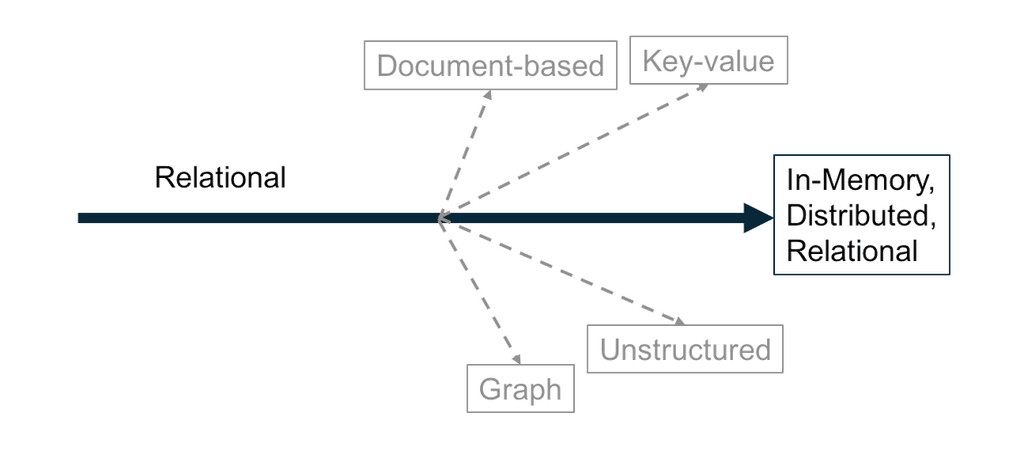
Strength of the Relational Model
Fortunately, the relational model has kept pace with modern workloads from webscale Internet applications, to the Internet of Things, to real-time analytics.
Two critical inventions have catalyzed the strength of the relational model:
- In-Memory Computing
With DRAM footprints increasing, and memory prices dropping, it becomes economically advantageous to keep high value data in memory
- In-Memory Computing
Distributed Systems
Advances in distributed programming deliver near unlimited scale to foundational infrastructure
Coupling these technical advancements with a relational model delivers a solution to tackle large data workloads with ease, and with structure built in.
FIGURE 3: A Relational Database Model
All for One, One for All
In the first round of the big data explosion, infrastructure tools became so abundant that far too quickly data practitioners were working more on data plumbing than data science. A cascading flow of infrastructure tools became as common as the data flow itself.
Now companies can store data in-memory, scale with distributed systems, and maintain a relational model from the outset. This provides the operational model and required performance, with the structure to immediately understand.











