This blog post describes a new approach to failover – the ability for SingleStore to continuously maintain live copies of the data on each SingleStore leaf node, and to switch over to those seamlessly when a fault occurs on the primary copy. In the new approach, copies of data are distributed more widely, and performance after a failure is better.
In SingleStoreDB Self-Managed 7.1, we introduce a new mechanism to place redundant copies of data within a SingleStore cluster. Building on top of our fast synchronous replication, SingleStore provides high availability. The new partition placement mechanism gracefully handles failures by making sure the workload that had formerly been on the failed node is distributed among multiple healthy nodes. Load-balancing the placement of partition replicas allows us to continue serving the workload with minimal performance degradation.
A New Approach, with Benefits
In previous versions of SingleStore, through SingleStoreDB Self-Managed 7.0, nodes are paired for replication purposes. So if one node fails, all its traffic is sent to its paired node, creating a “hot spot” that will have roughly double the traffic of other nodes. From the customer’s point of view, queries that hit the “hot spot” are prone to suddenly slowing down, while other queries will continue to operate at their former speed.
In SingleStoreDB Self-Managed 7.1, we have implemented an improvement that significantly reduces this problem. We now load balance replicas of the original, master partitions across multiple leaf nodes. This avoids creating a bottleneck when a leaf fails, while maintaining excellent overall availability.
Note. If you use Singlestore Helios, the concerns described in this blog post are managed for you by SingleStore. This blog post is only relevant for SingleStoreDB Self-Managed, whether hosted by on-premises servers or in the cloud.
The design of the new feature focuses on several goals:
1. Evenly Distribute the Workload after a Node Failure
In previous releases, SingleStore implemented a straightforward paired-leaf clustering scheme. Leaves form pairs. Within a pair, each leaf replicates the data of its paired leaf. It was simple to set up.
This scheme has an issue: when one leaf fails, its paired leaf now has the live copies of its original data, plus the just-promoted copies of the data that had formerly been served from the failed leaf. The healthy paired leaf now has two nodes worth of data, and will have to serve two nodes worth of queries. That makes this leaf overloaded and slow, compared to the remaining healthy leaves, which each continue to have only one node’s share of live data. Customers experience a significant reduction in cluster performance after hardware failure and inconsistencies in responsiveness.
In these previous versions, SingleStore paired leaves, and set up partition replication with each pair. The following picture illustrates a cluster with four leaves, split into two availability groups. The first pair is Leaf 1 and Leaf 2, while the second pair is Leaf 3 and Leaf 4. Partitions db_0 and db_1 have master copies on Leaf 1 and replicas on Leaf 2, while partitions db_2 and db_3 have their master copies on Leaf 2 and replicas on Leaf 1.
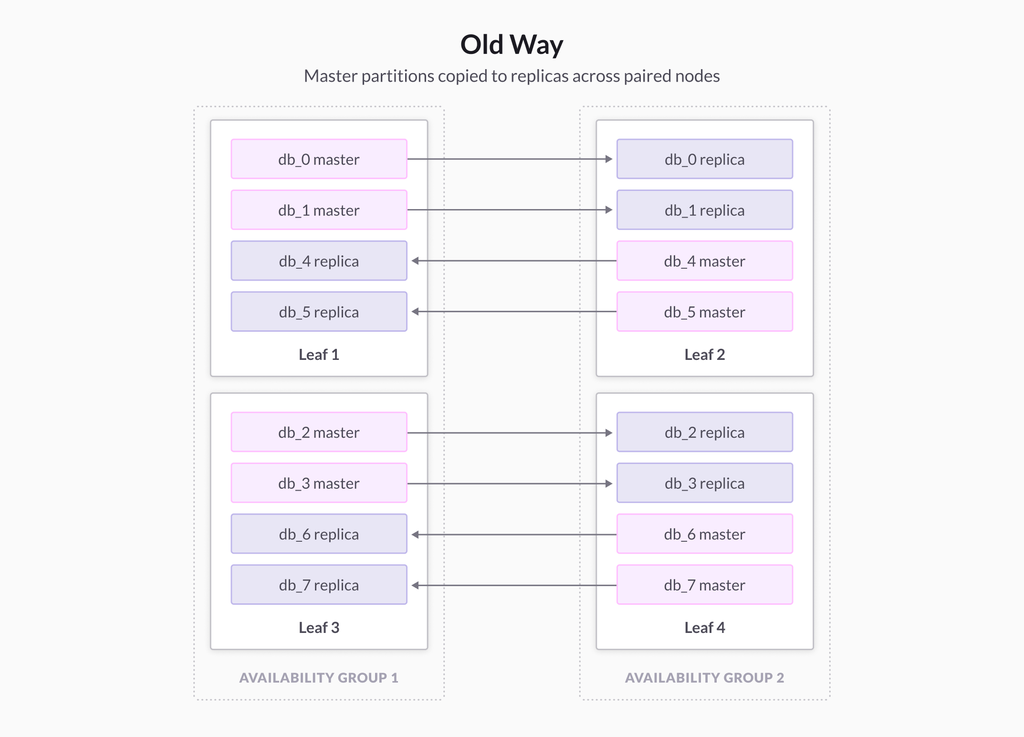
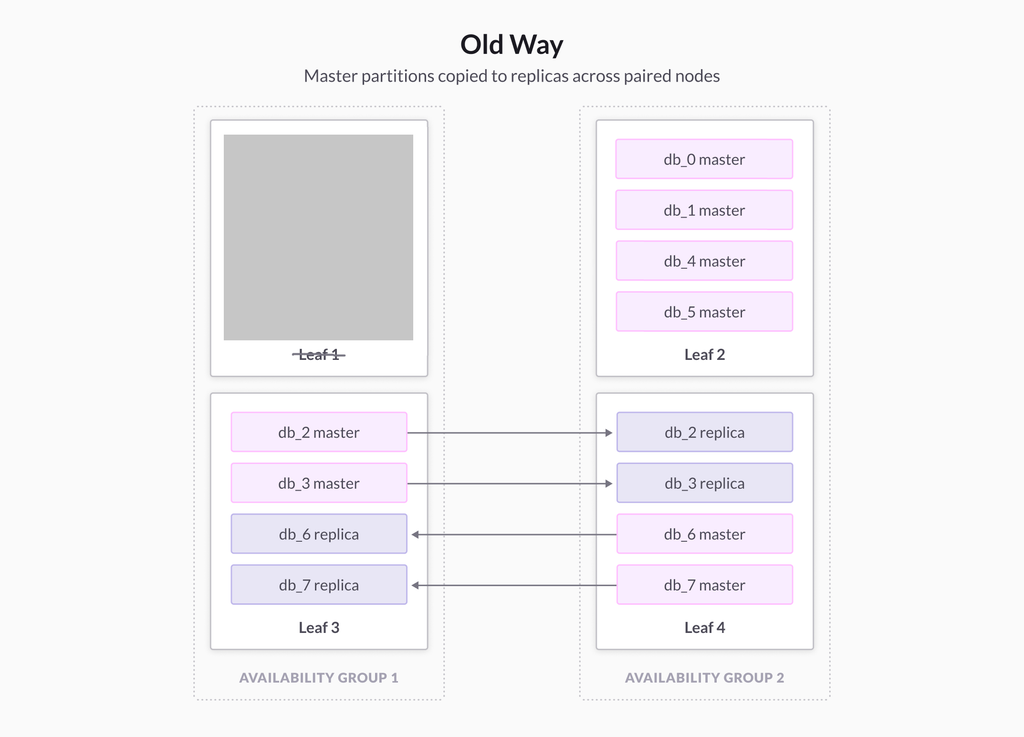
In this cluster setup, if Leaf 1 fails, the replicas of db_0 and db_1 on Leaf 2 must be promoted to masters to continue operation. Then Leaf 2 would see a 100% increase in workload, as it would have to serve queries for four master partitions, while Leaf 3 and Leaf 4 continue to each serve two master partitions each. Leaf 2 becomes a bottleneck.
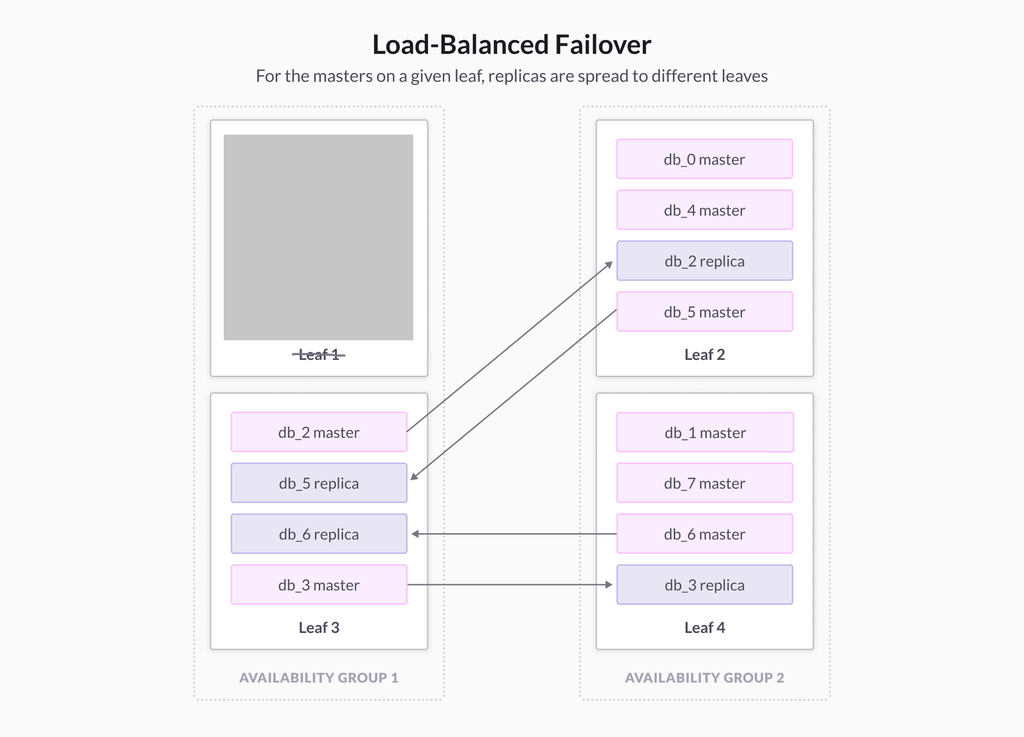
In load-balanced mode, SingleStore will place partitions in a different way. The partition placement algorithm will distribute primaries evenly, then distribute the replicas needed by any one leaf node across multiple other leaf nodes. In this new mode, db_0 will have a replica on Leaf 1, while db_1 will have a replica on Leaf 4. More generally, the master copies of a partition on any given leaf will get their replicas spread out across multiple nodes.

If Leaf 1 fails in this setup, SingleStore promotes the replica of db_0 on Leaf 2 to master, and the replica of db_1 on Leaf 4 to master. Each of these two leaves would see a 50% increase in workload, thus achieving a better distribution of the workload.
Larger clusters would see an even smoother distribution of the workload. More nodes means that the workload can be spread out to a larger number of nodes, each getting a smaller fraction of the workload from the failed node.
2. Create a Balanced Partition Placement
Previous versions of SingleStore maintain a good distribution of partitions on a given cluster. The load-balanced mode will place partitions in a way that all leaves have
- the same number of master partitions;
- the same number of replicas;
- failure resulting in the workload being equally spread among multiple other leaves.
We introduce the term fanout as the number of other leaves that will receive additional workload after node failure. The fanout is determined automatically, based on the size of the cluster.
3. Minimize Data Movement Necessary to Achieve a Balanced Partition Placement
A major goal with our design was to minimize the number of partitions we have to move. Moving a partition from one leaf to another involves copying substantial amounts of data. Promoting a replica of a partition to master involves pausing the workload while the change happens. While this locking might be very short, it increases the latency of running queries.
Additionally, this feature eliminates the need to provide buffer space on every single node to be able to handle twice the workload. This allows a higher utilization of the resources available on every host. The new mode also significantly reduces the likelihood of encountering out-of-memory (OOM) errors after a leaf failure.
With the new mode, you can make full use of all healthy leaves. In the older mode, if one leaf goes down, its (healthy) paired leaf will also be taken out of operation when you run REBALANCE. With the new mode, it is possible to call RESTORE REDUNDANCY to ensure that every partition still maintains a replica. This gives you more time and ease around fixing a failed leaf, or provisioning and adding a new one.
Memory, disk, and bandwidth requirements in normal operations remain the same for the new, load-balanced mode as for the older, paired mode.
Functional Description
The feature is enabled through a new variable called leaf_failover_fanout. This global variable is considered when running clustering operations, as well as CREATE DATABASE and REBALANCE operations. The master aggregator node is the only node that will read this variable. The variable is a sync var, to enable easier handling of master aggregator failovers.
The syntax for the global variable is:
SET GLOBAL leaf_failover_fanout = [ ‘load_balanced’ | **_'paired'_** ];
The default value of the global variable will be ‘paired’. In the initial version of this feature, these two options (load_balanced and paired) are the only allowed values.
In particular, leaf_failover_fanout having a value of ‘paired’ means that the cluster will have the same behavior of pairing leaves as it did in versions up to SingleStoreDB Self-Managed 7.0. That is, each leaf node replicates to one, and only one, other leaf node.
Setting leaf_failover_fanout to ‘load_balanced’ values enables the new mode, where the master copies of partitions are placed evenly on leaves, but duplication of each master copy as a replica onto a different leaf is planned separately.
For more specifics, see our documentation; in particular, the section on enabling high availability in load-balanced mode.
Customer Use Case Examples
Here we show how to accomplish two tasks using the new capability: how to create a database with automatic fanout; then, how to grow and shrink a cluster that is using load-balanced failover.
Creating a New Database with Automatic Fanout
A customer can set up a new cluster from scratch and start using the fanout behavior by setting the global variable to ‘load_balanced’. Following the initial setup of the cluster with all the ADD AGGREGATOR/LEAF commands:
set global leaf_failover_fanout=’load_balanced’;
CREATE DATABASE db;
This uses the default partitions and replicates them in a balanced way. The fanout is automatically determined based on the number of leaves available, as described below.
Growing and Shrinking a Cluster
In the new mode, customers continue to use the same sequence of steps to add or remove leaves. Setting the global variable to ‘load_balanced’ makes sure that subsequent rebalances cause the fanout to change to the appropriate value.
ADD LEAF root@’x.x.x.x’:y; // for every new leaf
Further, enable the feature by setting the global variable
SET GLOBAL leaf_failover_fanout=’load_balanced’;
Since setting the global variable will not trigger any expensive operations, the administrator will have to run:
REBALANCE PARTITIONS ON db; // execute for every database.
Any subsequent rebalance operations, whether triggered manually or by add/remove leaf commands, will follow the new scheme for partition placement.
Upgrading to the New Behavior
For existing SingleStore users, the primary way to transition to the fanout behavior after upgrade from SingleStoreDB Self-Managed 7.0, or previous versions, to SingleStoreDB Self-Managed 7.1 or later, will be to set the global variable to ’load_balanced’ and run REBALANCE on all the databases.
SingleStore does not do this in upgrade on this initial release of the feature, since the rebalance is a long operation – it can take an hour or more. In order to enable the feature post-upgrade, execute the following commands:
SET GLOBAL leaf_failover_fanout=’load_balanced’;
REBALANCE PARTITIONS ON db; -- execute for every database.q
Choosing Whether to Load Balance Clusters
Using the new load balanced option is, well, optional. The defalt is to continue using the paired option from previous releases. How to decide which option to use?
For most new databases, the new option has no upgrade costs, and no noticeable runtime costs. But, if and when you do have leaf nodes crash, the new option gives you better performance, post-crash. It also requires less buffer to be set aside for each node, saving you either space on your own servers, or money for operations in the cloud. So we recommend using the new option for new databases.
The only question, then, is whether it’s worthwhile to transition to the new feature for existing databases. As described above, you simply turn load balance on, then rebalance your database. What will this cost you?
- Bandwidth. The rebalance operation necessary to transition to the new behavior on an existing SingleStore cluster will require moving a lot of partitions. If your cloud provider charges you for internal cluster traffic, this can turn into a monetary cost.
- Time. You have to run a full rebalance of your database. This may take an hour, or hours. SingleStore can advise you on how long a rebalance is likely to take.
- Disk space. The rebalance operation will create additional copies of your data for the duration it takes to move it. Having at least 30% free disk is recommended before making the switch.
Here’s how to estimate the costs. For memory and disk, you will need about one-third free memory and disk space, over and above the size of the database.
For bandwidth, the number of partitions that need to be moved during the transition is:
N * (fanout-1) / fanout
where N is the number of master partitions (and is also the number of replica partitions).
Fanout is approximated by: # leaves / 2
This formula yields the number of partitions that need to be moved for specific numbers of leaves. For small clusters, half or more of the replica partitions are moved; for larger clusters, the number of replica partitions that need to be moved approaches 100%.
Conclusion
We recommend that you use load-balanced failover for all your new databases. It provides better performance after a node failure, giving you more flexibility as to when you have to rebalance. It also reduces your need for buffer space, saving you money.
For existing databases, we recommend that you move to load-balanced failover the next time you rebalance your cluster. If that need is not otherwise imminent, you can decide whether it’s worth rebalancing simply to move to the new features. We believe that, in most cases, it will be worthwhile to move in the near future.
If you are interested in learning more, and you are not yet a SingleStore user, you can try SingleStore for free, or contact SingleStore to find out more.

_featured.png?height=187&disable=upscale&auto=webp)



