
SingleStore is a real-time data platform with powerful, scalable operational and transactional capabilities for intelligent applications and analytics. SingleStore’s patented Universal Storage engine provides real-time ingestion with ultra low latency and high concurrency transactional, analytical, vector, semantic or hybrid queries against memory optimized columnstore or rowstore tables.
This gives SingleStore substantial advantages in use cases where data needs to be transacted, analyzed or contextualized in near real time. We call this hybrid transactional-analytical processing (HTAP).
Some of the most common questions with transactional and HTAP use cases — or even migrations from MySQL — center around referential integrity and how to support foreign key relationships across a sharded system where foreign keys aren’t common. This blog answers that question by looking at a simple catalog, subscriber and subscription example to demonstrate how to uphold foreign key relationships and high-performance distributed SQL via application inserts and in pipelines without defining foreign keys in DDL.
For a detailed overview of how to handle multiple unique keys in SingleStore with a similar approach, check out this blog by SingleStore and Laravel community expert Jack Ellis. For a detailed overview of how SingleStore is optimized for transactional workloads, see “Build Faster Transactional Apps With SingleStore: Part I and Part II.”
Catalogs, subscribers and subscriptions case
Imagine an application that drives delivery of subscribed content via email. Managing this mail list might reasonably entail:
- Ensuring that all inserts catalogs belong to an organization
- All subscribers belong to an org that does not yet contain the subscriber’s email
- Al subscriptions belong to a distinct subscriber and catalog
This blog shows how SingleStore can easily handle enforcing this relationship with app-logic and without foreign keys.
Initial design considerations
At the core, referential integrity is the process of managing relationships between tables in a database. In most relational databases like MySQL or PostgreSQL, foreign keys and unique keys are an accepted performance hit to guarantee bad inserts do not commit. First and foremost, it is crucial to call out that referential integrity typically is, and always should be, enforced at the application layer. No database key or process should solely enforce these relationships — it is the application's job to ensure the consistency of the ACID transaction written. Application logic should:
- Enforce uniqueness of the required fields datatype, and save the primary key for unique update/upsert record
- Ensure inserts contain the required relational key values
- Encode the logic of the uniqueness or referential check in the insert statement or pipeline procedure
With proper application-side logic in place, foreign key relationships or uniqueness has already been determined; the keys are there as insurance to enforce this relational integrity across tables and make sure no bad data is inserted. This is particularly true in microservices-based architectures where eventual-consistency is an inherent design principle. Yet, we lean on OLTP-only solutions to enforce these keys as insert volume increases and accept the performance hit.
SingleStore is designed to minimize latency and maximize insert volume across a sharded three-tier storage model. SingleStore is MySQL wire protocol compliant, but it is not a MySQL build. There are many features in SingleStore not in MySQL, and a few in MySQL that are not supported in SingleStore (outlined here). Notably for this blog’s purpose:
- SingleStore supports only one enforced primary or unique key
- SingleStore does not currently support foreign keys
Managing foreign keys or multiple unique keys adds operational overhead that is not typically worthwhile compared to adding checks into the insert itself — especially when looking to dramatically speed up transactions — as outlined in the Fathom blog on multiple unique column example. Outside of application level logic and keys in a table, unenforced unique constraints can help flag suspected violations that make it through the logic.
In instances where there are multiple unique key requirements and uniqueness of a field is guaranteed by datatype (like a hash-value or auto_incremented value), consider removing or un-enforcing the unique key on these values and assign the primary key based on update and upsert requirements. Other examples describe inserting into one table without uniqueness constraints rapidly, then using conditional selects to insert into a secondary table which is used for queries.
Since these uniqueness checks have more examples, this blog focuses primarily on foreign key checks. SingleStore’s memory-optimized query engine ensures these filter based insert select statements uphold relationships while inserting data in near-real time.
Step 1: Loading Orgs and Catalogs with conditional inserts
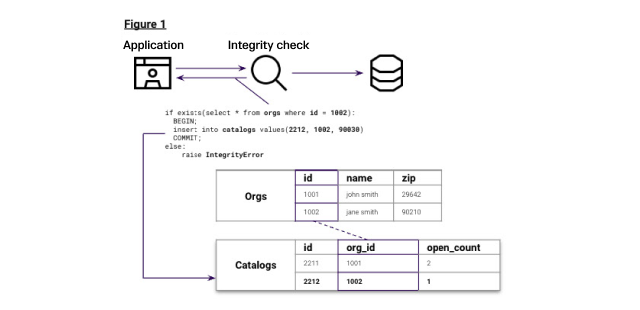
The first foreign key relationship we need to match is between Orgs and Catalogs, where write transactions should contain logic to ensure any insert to catalogs checks the 'org_id' for existence in orgs as id first. Figure 1 explains this relationship with an example of this insert as a nested transaction sent from the application.
The first step is to create the orgs and load 10 initial records:
1-- Orgs 2DROP TABLE IF EXISTS orgs; 3CREATE TABLE `orgs` 4( `id` bigint(10) unsigned NOT NULL AUTO_INCREMENT,5 `created_at` timestamp NULL DEFAULT NULL, 6 `updated_at` timestamp NULL DEFAULT NULL, 7 `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL, 8 `send_cost` decimal(4,2) NOT NULL, 9 `active` tinyint(4) NOT NULL, 10 PRIMARY KEY (`id`) USING HASH, 11 SHARD KEY `__SHARDKEY` (`id`), 12 SORT KEY `__UNORDERED` () 13) ; 14---- Insert 10 records manually to org table15INSERT INTO orgs (id, created_at, updated_at, name, send_cost, active)16VALUES 17 (1, '2023-10-01 00:00:00', '2023-10-01 00:00:00', 'PearStreet', 1.00, 1),18 (2, '2023-10-15 00:00:00', '2023-10-20 00:00:00', 'YourFavCompnay', 2.00, 1),19 (3, '2023-11-01 00:00:00', '2023-11-02 00:00:00', 'GetOutside', 3.00, 1),20 (4, '2023-11-15 00:00:00', '2023-11-19 00:00:00', 'Partner, Partner, and Partner', 4.00, 1),21 (5, '2023-12-01 00:00:00', '2023-12-01 00:00:00', 'Avenue5', 5.00, 1),22 (6, '2023-12-15 00:00:00', '2023-12-20 00:00:00', 'Big Inc', 6.00, 1),23 (7, '2024-01-01 00:00:00', '2024-01-02 00:00:00', 'Small Co', 7.00, 1),24 (8, '2024-01-15 00:00:00', '2024-01-20 00:00:00', 'Acme Company', 8.00, 1),25 (9, '2024-02-01 00:00:00', '2024-02-05 00:00:00', 'Wayne Enterprises', 9.00, 1),26 (10, '2024-02-15 00:00:00', '2024-02-20 00:00:00', 'The Database Beat', 10.00, 1);
Next, create the Catalogs table:
1DROP TABLE IF EXISTS catalogs; 2CREATE TABLE `catalogs` (3 `id` bigint(10) unsigned NOT NULL AUTO_INCREMENT,4 `org_id` int(10) unsigned DEFAULT NULL,5 `parent_id` int(11) unsigned DEFAULT NULL,6 `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,7 `active` tinyint(4) NOT NULL DEFAULT '1',8 `created_at` timestamp NULL DEFAULT NULL,9 `updated_at` timestamp NULL DEFAULT NULL,10 SORT KEY `__UNORDERED` (), 11 SHARD KEY (id), 12 PRIMARY KEY (id) USING HASH13) ;
Let’s now mimic the application transaction in Figure 1, attempting to insert a new one-off row over a database command into catalogs where the ‘org_id’ does not exist in orgs.id. The does not insert any records because no orgs.id is 9999.
1INSERT INTO catalogs (id, org_id, name, active, created_at, updated_at)2SELECT 9999, 1, 'Villains Inc', 0, '2023-12-07 00:27:50', '2024-02-18 04:10:28'3FROM dual4WHERE EXISTS (SELECT 1 FROM orgs o WHERE o.id = 9999);5Select * from catalogs;
Inserts following the preceding, or Figure 1, can be batched into concurrent multi-insert statements with the app of choice — or batched in stored procedures in insert all statements.
Perhaps the application has queues that push writes to an S3 bucket or Kafka topic as they are created. In this case, we can leverage a stored procedure to perform our referential checks before inserting records from a SingleStore pipeline into a table. The next section illustrates how to establish pipelines into stored procedures to stream data into catalogs, subscribers and subscriptions while checking for referential integrity.
Step 2: Streaming catalogs, subscribers and subscriptions with Pipelines into procedures
SingleStore pipelines provide real-time ingest by streaming data directly into partitions in parallel. Pipelines can be created to stream data directly into a table or into a stored procedure, where it can be manipulated before insertion. This procedural approach allows for referential integrity checks as described in Figure 1 directly in the stream. All three tables will follow this procedure and pipeline format:
1--- Pipeline Into Stored Procedure Relationship Check Template 2DELIMITER //3CREATE OR REPLACE PROCEDURE <SP_name>(4batch QUERY(5<table_fields coming from pipeline>6)7)8AS9 BEGIN10 INSERT INTO <table_name>()11 SELECT <insert all columns>12 FROM batch b13 WHERE EXISTS (SELECT 1 FROM <table_name> WHERE b.<field> = <table_name.field>)14 END //15DELIMITER;16----------------17--- Pipeline Template18CREATE or replace PIPELINE <Pipeline_name>19AS LOAD DATA -- <Link or Credentials>20BATCH_INTERVAL 250021DISABLE OFFSETS METADATA GC22INTO PROCEDURE <Procedure_name>23FIELDS TERMINATED BY ',' optionally ENCLOSED BY '\"' ESCAPED BY '\\'24LINES TERMINATED BY '\n' STARTING BY '' NULL DEFINED BY ''25IGNORE 1 LINES -- if files contain headers ;
Catalogs
We can guarantee Catalogs belong to an existing org with the following procedure and pipeline:
1-- Procedure `catalogs_insert_check`2DELIMITER //3CREATE OR REPLACE PROCEDURE catalogs_insert_check4(batch QUERY(5 `id` bigint(10) unsigned NOT NULL,6 org_id int(10) unsigned, 7 parent_id int(11) unsigned, 8 name varchar(255), 9 active tinyint(4), 10 created_at timestamp, 11 updated_at timestamp12 )13)14AS15 BEGIN16 INSERT INTO catalogs(org_id, parent_id, name, active, created_at, updated_at)17 SELECT org_id, parent_id, name, active, created_at, updated_at18 FROM batch b19 WHERE EXISTS (SELECT 1 FROM orgs WHERE b.org_id = orgs.id);20 END //21DELIMITER;22------------------23-- Pipeline Into Procedure `catalogs_insert_check`24CREATE PIPELINE `catalogs`25AS LOAD DATA S3 's3://<Redacted>/*'26CONFIG '{"region": "us-east-1"}'27CREDENTIALS '{"aws_access_key_id": "<REDACTED>", "aws_secret_access_key": "<REDACTED>", 28"aws_session_token": "<REDACTED>"}'29BATCH_INTERVAL 250030DISABLE OFFSETS METADATA GC31INTO PROCEDURE `catalogs_insert_check`32FIELDS TERMINATED BY ',' ENCLOSED BY '\"' ESCAPED BY '\\'33LINES TERMINATED BY '\r\n' STARTING;
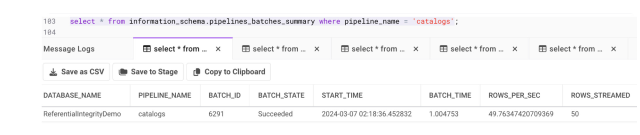
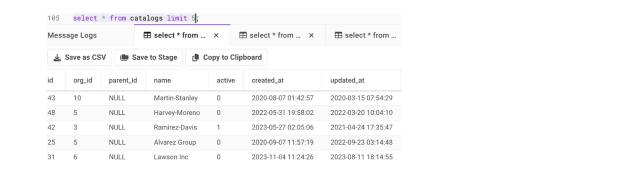
Subscribers
Inserts to subscribers first check if the subscriber exists in a valid organization, then that their email is not already a subscriber in that org, as shown in Figure 2. This check handles referential integrity and uniqueness.
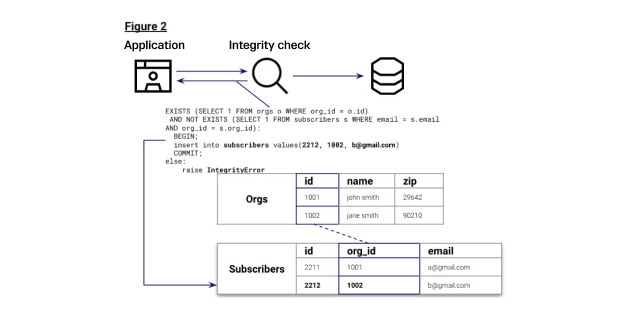
The table DDL, stored procedure for checking inserts and pipeline for subscribers are outlined here:
1-- DDL for Subscribers Table2CREATE TABLE `subscriptions` (3 `id` bigint(10) unsigned NOT NULL AUTO_INCREMENT,4 `created_at` timestamp NULL DEFAULT NULL,5 `updated_at` timestamp NULL DEFAULT NULL,6 `subscriber_id` bigint(10) DEFAULT NULL,7 `catalog_id` bigint(10) DEFAULT NULL,8 `upload_id` int(10) DEFAULT NULL,9 `group_id` int(10) DEFAULT NULL,10 `tags` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,11 `last_delivered` timestamp NULL DEFAULT NULL,12 `delivered_count` smallint(6) DEFAULT NULL,13 `open_count` smallint(6) DEFAULT NULL,14 `click_count` smallint(6) DEFAULT NULL,15 SORT KEY `__UNORDERED` (),16 SHARD KEY (id),17 PRIMARY key (`id`) 18) ;19------------------20-- Subscribers_insert_check Procedure 21DELIMITER //22CREATE OR REPLACE PROCEDURE subscribers_insert_check23(batch query(24 `id` bigint(10) unsigned NULL,25 `created_at` timestamp NULL,26 `updated_at` timestamp NULL, 27 `org_id` int(10) NULL, 28 `upload_id` int(10) unsigned NULL, 29 `email` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 30 `first` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 31 `last` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 32 `street` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 33 `city` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 34 `company` varchar(128) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 35 `state` char(2) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 36 `zip` char(10) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 37 `phone` varchar(30) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 38 `complaint_count` int(11) NULL, 39 `last_open` datetime NULL, 40 `last_click` datetime NULL, 41 `lcount` tinyint(4) NULL)42 ) 43AS44 BEGIN45 INSERT INTO subscribers(id, 46created_at,updated_at,org_id,upload_id,email,first,last,street,city,company,state,zip,phone,complaint_count,last_open,last_47click,lcount)48 SELECT b.id, 49b.created_at,b.updated_at,b.org_id,b.upload_id,b.email,b.first,b.last,b.street,b.city,b.company,b.state,b.zip,b.phone,b.compl50aint_count,b.last_open,b.last_click,b.lcount51 FROM batch b52 WHERE EXISTS (SELECT 1 FROM orgs o WHERE b.org_id = o.id)53 AND NOT EXISTS (SELECT 1 FROM subscribers s WHERE b.email = s.email AND b.org_id = s.org_id);54 END //55DELIMITER;56------------------57-- Subscribers Pipeline58CREATE or replace PIPELINE `subscribers`59AS LOAD DATA S3 's3://<Redacted>/*'60CONFIG '{"region": "us-east-1"}'61CREDENTIALS '{"aws_access_key_id": "<REDACTED>", "aws_secret_access_key": "<REDACTED>", "aws_session_token": 62"<REDACTED>"}'63BATCH_INTERVAL 250064DISABLE OFFSETS METADATA GC65INTO PROCEDURE `subscribers_insert_check`66FIELDS TERMINATED BY ',' ENCLOSED BY '"' ESCAPED BY '\\' 67LINES TERMINATED BY '\r\n' STARTING BY '' 68IGNORE 1 LINES69FORMAT CSV;
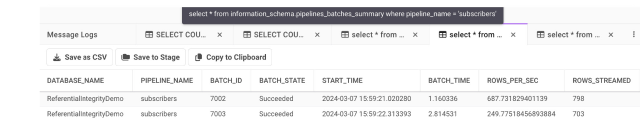
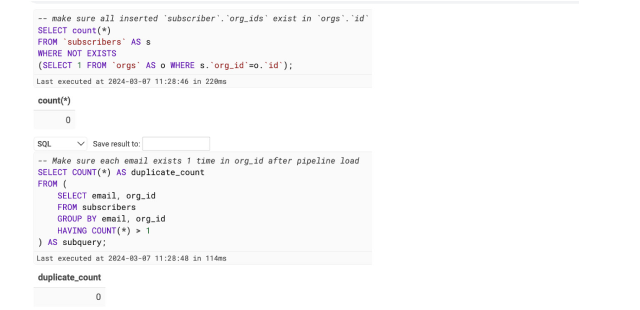
We can now validate that no org_id does not exist as an id in orgs, and that each subscribers’ email is unique for that an org_id as follows:
1-- make sure all inserted `subscriber`.`org_ids` exist in `orgs`.`id`2SELECT count(*)3FROM `subscribers` AS s4WHERE NOT EXISTS 5(SELECT 1 FROM `orgs` AS o WHERE s.`org_id`=o.`id`);6-- Make sure each email exists 1 time in org_id after pipeline load 7SELECT COUNT(*) AS duplicate_count 8FROM (9 SELECT email, org_id 10 FROM subscribers 11 GROUP BY email, org_id 12 HAVING COUNT(*) > 113 HAVING COUNT(*) > 114) AS dup_count;15
We’ll set the stage with one last table, subscriptions with its own referential integrity requirements, then test the pipeline with purposefully bad batches.
Subscriptions
The table subscriptions stores information on subscriptions to different organizations' catalog items. All inserts must check that the subscription contains a valid catalog_id and valid subscriber id, and that the subscription to the catalog item is unique for this subscriber. This is outlined here in Figure 3.
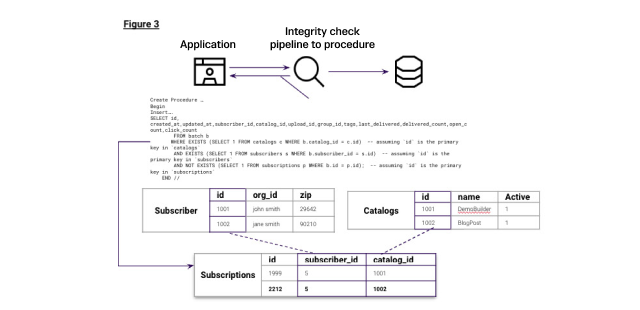
The table DDL, stored procedure for checking inserts and pipeline for subscribers are outlined here:
1-- DDL for Subscribers Table2CREATE TABLE `subscriptions` (3 `id` bigint(10) unsigned NOT NULL AUTO_INCREMENT,4 `created_at` timestamp NULL DEFAULT NULL,5 `updated_at` timestamp NULL DEFAULT NULL,6 `subscriber_id` bigint(10) DEFAULT NULL,7 `catalog_id` bigint(10) DEFAULT NULL,8 `upload_id` int(10) DEFAULT NULL,9 `group_id` int(10) DEFAULT NULL,10 `tags` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,11 `last_delivered` timestamp NULL DEFAULT NULL,12 `delivered_count` smallint(6) DEFAULT NULL,13 `open_count` smallint(6) DEFAULT NULL,14 `click_count` smallint(6) DEFAULT NULL,15 SORT KEY `__UNORDERED` (),16 SHARD KEY (id),17 PRIMARY key (`id`) 18) ;19------------------20-- Subscribers_insert_check Procedure 21DELIMITER //22CREATE OR REPLACE PROCEDURE subscribers_insert_check23(batch query(24 `id` bigint(10) unsigned NULL,25 `created_at` timestamp NULL,26 `updated_at` timestamp NULL, 27 `org_id` int(10) NULL, 28 `upload_id` int(10) unsigned NULL, 29 `email` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 30 `first` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 31 `last` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 32 `street` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 33 `city` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 34 `company` varchar(128) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 35 `state` char(2) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 36 `zip` char(10) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 37 `phone` varchar(30) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL, 38 `complaint_count` int(11) NULL, 39 `last_open` datetime NULL, 40 `last_click` datetime NULL, 41 `lcount` tinyint(4) NULL)42 ) 43AS44 BEGIN45 INSERT INTO subscribers(id, 46created_at,updated_at,org_id,upload_id,email,first,last,street,city,company,state,zip,phone,complaint_count,last_open,last_47click,lcount)48 SELECT b.id, 49b.created_at,b.updated_at,b.org_id,b.upload_id,b.email,b.first,b.last,b.street,b.city,b.company,b.state,b.zip,b.phone,b.compl50aint_count,b.last_open,b.last_click,b.lcount51 FROM batch b52 WHERE EXISTS (SELECT 1 FROM orgs o WHERE b.org_id = o.id)53 AND NOT EXISTS (SELECT 1 FROM subscribers s WHERE b.email = s.email AND b.org_id = s.org_id);54 END //55DELIMITER;56------------------57-- Subscribers Pipeline58CREATE or replace PIPELINE `subscribers`59AS LOAD DATA S3 's3://<Redacted>/*'60CONFIG '{"region": "us-east-1"}'61CREDENTIALS '{"aws_access_key_id": "<REDACTED>", "aws_secret_access_key": "<REDACTED>", "aws_session_token": 62"<REDACTED>"}'63BATCH_INTERVAL 250064DISABLE OFFSETS METADATA GC65INTO PROCEDURE `subscribers_insert_check`66FIELDS TERMINATED BY ',' ENCLOSED BY '"' ESCAPED BY '\\' 67LINES TERMINATED BY '\r\n' STARTING BY '' 68IGNORE 1 LINES69FORMAT CSV;
We can now validate that no org_id does not exist as an id in orgs, and that each subscribers’ email is unique for that an org_id as follows:
1-- make sure all inserted `subscriber`.`org_ids` exist in `orgs`.`id`2SELECT count(*)3FROM `subscribers` AS s4WHERE NOT EXISTS 5(SELECT 1 FROM `orgs` AS o WHERE s.`org_id`=o.`id`);6-- Make sure each email exists 1 time in org_id after pipeline load 7SELECT COUNT(*) AS duplicate_count 8FROM (9 SELECT email, org_id 10 FROM subscribers 11 GROUP BY email, org_id 12 HAVING COUNT(*) > 113) AS dup_count;
We can verify no records violating the filter were inserted with:
1SELECT COUNT(*) AS invalid_rows_count2FROM subscriptions s3WHERE NOT EXISTS (SELECT 1 FROM catalogs c WHERE s.catalog_id = c.id)4 OR NOT EXISTS (SELECT 1 FROM subscribers sub WHERE s.subscriber_id = sub.id)5 OR EXISTS (SELECT 1 FROM subscriptions p WHERE s.id = p.id AND s.catalog_id != p.catalog_id AND s.subscriber_id != 6p.subscriber_id);

With this, our imagined subscription management use case has been set up to stream inserts into catalogs, subscribers and subscriptions tables respectively, while first performing the required referential integrity checks.
Trust and verify with subscriptions
Let’s now dive deeper into subscriptions to see batches that should and should not insert, following our initial load of 2,000 subscription records. Figure 3 represents the attempted insert of the four rows below the line, where the preceding shows existing values.
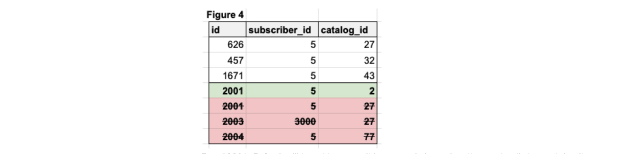
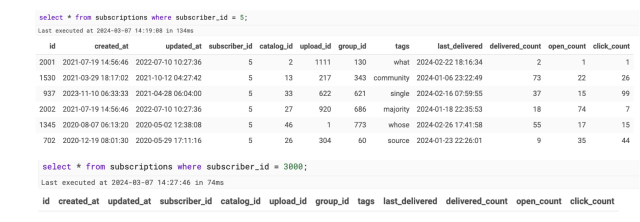
Row 2001, 5, 2,... will insert because it has an existing subscriber and a distinct catalog item within. When looking at all other subscriptions for subscriber_id = 5. Row 2002, 5, 27, … does not insert because subscriber_id =5 contains an existing entry where catalog_id = 27. Row 2003, 3000, 27, … will not insert because there is no existing subscriber_id or id in the subscribers table with id = 3000. Finally, row 2004, 5, 77, … will not insert because there is no catalog_id or id in the catalogs table with id = 77.
The logic of the insert checks has been previously validated, but let’s purposely add these four bad lines (in full) as a CSV file to our existing S3 bucket to see if the pipeline procedure rejects these inserts as expected.
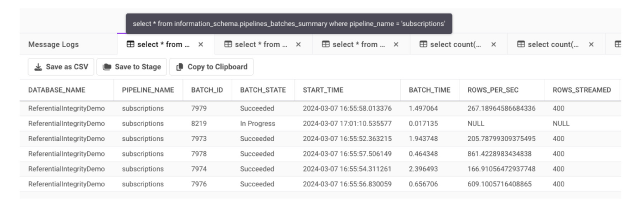
After adding the new batch, called ‘BadLines_refint_subscriptions.csv, the running pipeline will automatically pick up this new file in the next batch interval (every 2.5 seconds as by default here).
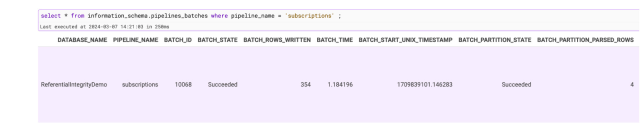
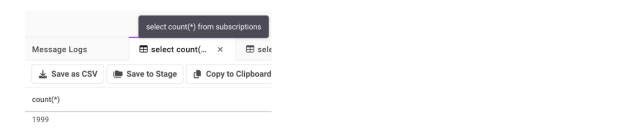
We see four rows parsed; however, when we select into the table we can see only one successfully inserted:
SingleStore does not support foreign keys in DDL, but as demonstrated in this blog we can confirm using filters in insert…select… Statements can be a scalable manner to maintain referential integrity or uniqueness checks with inserts or stored procedures, and SingleStore pipelines.
Taking the next step
SingleStore is a powerful database designed specifically to support operational queries, CRUD, AI and real-time streaming analytics across a scale-out distributed architecture with sub-second latency — even at high concurrency. While foreign keys are not currently supported, SingleStore can quickly perform these checks with logic in the insert, either in the transaction itself or in pipeline and procedure.
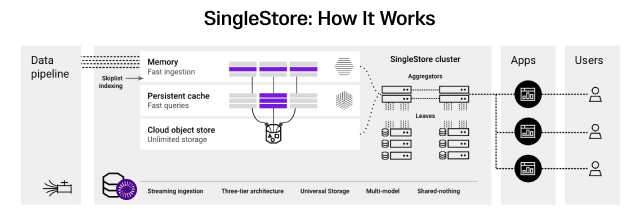
SingleStore’s best-in class approach is driven by its patented Universal Storage, a memory-optimized multimodal columnstore that optimizes for speed and concurrency across a clustered system:
Still skeptical? Don’t take our word for it; test it yourself. Spin up a free trial and follow along with this blog, or explore some of our other use-case specific walkthroughs here. At whatever size or scale you’re looking to test, we can help prove the value of multimodal HTAP for your transactional or analytical use case.













.jpg?width=24&disable=upscale&auto=webp)
