
In today’s data-driven world, the ability to quickly analyze large volumes of information is paramount.
.png?width=736&disable=upscale&auto=webp)
Data teams, whether working on real-time streaming analytics, interactive dashboards or machine learning workloads, need databases that can balance speed, scalability and flexibility. Two popular choices in the modern data stack are SingleStore and ClickHouse. Both databases are designed to handle analytic, data warehouse workloads efficiently, but they differ in architecture, ecosystem integration, scalability and use-case fit. In this article, we’ll dive deep into the capabilities and strengths of SingleStore and ClickHouse to help you decide which one best aligns with your organizational needs.
Understanding SingleStore vs. Clickhouse
What is SingleStore?
SingleStore is a real-time, distributed SQL database. With familiar SQL tooling and MySQL wire protocol compatibility, SingleStore eliminates the need for specialized databases and simplifies database architectures.
SingleStore is also built to handle multiple data types — including JSON, time-series, geospatial and full-text search— delivering high-speed data ingestion on a unified transactional (OLTP) and analytical (OLAP) foundation.
SingleStore architecture

What is ClickHouse?
ClickHouse, developed by Yandex and maintained by ClickHouse, Inc., is a real-time data warehouse and open-source database that uses a highly performant columnar database built primarily for analytics. It is known for its exceptionally fast query performance on large datasets. ClickHouse leverages vertical partitioning, vectorized query execution and advanced compression techniques, making it a go-to solution for log analytics, observability and time-series workloads.
Key differences between SingleStore and ClickHouse include:
Aspect | SingleStore | ClickHouse |
Primary focus | Converged (OLTP + OLAP) workloads | High-performance analytical (OLAP) workloads |
Storage model | Universal columnstore for both OLTP and OLAP | Columnar storage optimized for analytical queries |
Query execution engine | Distributed SQL engine with compute pushdown | MPP engine with vectorized execution and compression |
Data ingestion | Real-time ingestion with inbuilt pipeline support for multiple sources like Kafka, S3, Iceberg format, JSON | High ingestion rates, typically with batch insert |
Data updates | Supports standard SQL DML (INSERT, UPDATE, DELETE) for transactions | Limited support; best for append-only or batch updates |
Workload flexibility | Handles mixed workloads (operational + analytical) in one system | Primarily optimized for analytical, read-heavy workloads |
Scalability | Both horizontal and vertical online scaling | Horizontal scaling by adding more nodes; excels at massive scale analytics |
Compression | High compression ratio (60-70%) | Support compression |
Sharding | Automatic | Manual |
Data transformation | Inbuilt support of TRANSFORM using pipelines | No built-in syntax or feature |
Use case fit | Real-time analytics, mixed workload consolidation, simplifying data infrastructure | Analytical queries |
Vector data types | Mature | New |
JSON support | Fully integrated JSON data type and functions | “Object” data type and related functions to handle JSON data. |
CDC out | Inbuilt CDC out feature | Not inbuilt |
WASM | Allows you to create UDFs/TVFs in a language of your choice and run them in a sandboxed environment for enhanced security | No support |
How to setup SingleStore and ClickHouse
SingleStore
- On-premises. Please follow the instructions here to download and install SingleStore.
- Cloud. Spin up your cluster on the cloud of your choice (AWS/GC/Azure) using the link here.
ClickHouse
- On-premises. Follow the instructions to download and install ClickHouse.
SingleStore and ClickHouse Configuration
ClickHouse
Installation type: Cloud (Region: Ohio)
ClickHouse server version 24.8
Scale up to 48 vCPU, 192 GiB (From 6 vCPU, 24 GiB)
Engine: MergeTree
SingleStore
Installation type: Cloud (Region: Ohio)
SingleStore version: 8.7.1
Size: S-1, 8vCPU , 64 GiBPartition: 32
Table type: Columnstore
Performance
Now that we've compared features, let's dive into SQL query performance — where real-world use cases truly separate the two. We’ll look at five complex queries that test everything from joins to aggregations, and see how SingleStore consistently outperforms ClickHouse in speed, efficiency and accuracy.
Query performance comparison
Number of records on both sides: 20M
.png?width=1024&disable=upscale&auto=webp)
.png?width=1024&disable=upscale&auto=webp)
Query comparison
Query 1
.png?width=1024&disable=upscale&auto=webp)
.png?width=1024&disable=upscale&auto=webp)
Query 2
.png?width=1024&disable=upscale&auto=webp)
.png?width=1024&disable=upscale&auto=webp)
Query 3
.png?width=1024&disable=upscale&auto=webp)
.png?width=1024&disable=upscale&auto=webp)
Query 4
.png?width=1024&disable=upscale&auto=webp)
.png?width=1024&disable=upscale&auto=webp)
Query 5
.png?width=1024&disable=upscale&auto=webp)
.png?width=1024&disable=upscale&auto=webp)
Based on performance benchmarks, SingleStore demonstrates a clear and substantial speed advantage over ClickHouse. Query execution metrics show that SingleStore is 85% to 95% faster, making it a significantly more efficient option for high-performance workloads.
Even more, internal testing on larger datasets using complex multi-join queries from the Trips benchmark confirms that SingleStore continues to outperform ClickHouse right out of the box.
Data loading comparison
Total number of rows: 100 million
SingleStore load time: 134 seconds
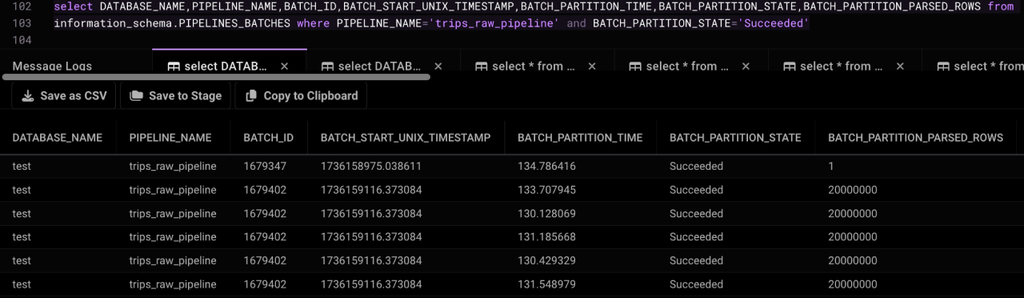
ClickHouse load time: No support to monitor each pipeline individually.
When it comes to performance, SQL flexibility and enterprise-grade capabilities, SingleStore clearly stands out over ClickHouse. From support for complex SQL queries to transactional consistency and real-time analytics, SingleStore not only matches but exceeds expectations in areas where ClickHouse often falls short.
For teams seeking a high-performance database that combines OLTP and OLAP workloads without compromising on speed or functionality, SingleStore proves to be the smarter, future-ready choice.
Frequently Asked Questions





_feature.png?height=187&disable=upscale&auto=webp)






.png?width=24&disable=upscale&auto=webp)

