SingleStore Notebooks
New


How to Build LLM Apps that can See Hear Speak
Notebook
Note
This tutorial is meant for Standard & Premium Workspaces. You can't run this with a Free Starter Workspace due to restrictions on Storage. Create a Workspace using +group in the left nav & select Standard for this notebook. Gallery notebooks tagged with "Starter" are suitable to run on a Free Starter Workspace
Demo Architecture
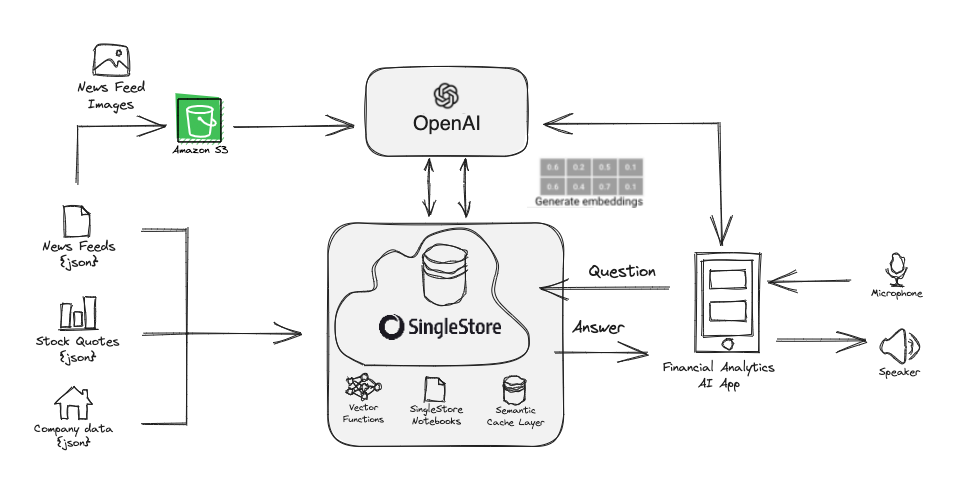
Create and use the database llm_webinar
In [1]:
1
%%sql2
DROP DATABASE IF EXISTS llm_webinar;3
CREATE DATABASE llm_webinar;
Out [1]:
Action Required
Make sure to select a database from the drop-down menu at the top of this notebook. It updates the connection_url to connect to that database.
Create tables
In [2]:
1
%%sql2
CREATE TABLE `stockTable` (3
`ticker` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,4
`created_at` datetime DEFAULT NULL,5
`open` float DEFAULT NULL,6
`high` float DEFAULT NULL,7
`low` float DEFAULT NULL,8
`close` float DEFAULT NULL,9
`volume` int(11) DEFAULT NULL,10
SORT KEY (ticker, created_at desc),11
SHARD KEY (ticker)12
);13
14
CREATE TABLE newsSentiment (15
title TEXT CHARACTER SET utf8mb4,16
url TEXT,17
time_published DATETIME,18
authors TEXT,19
summary TEXT CHARACTER SET utf8mb4,20
banner_image TEXT,21
source TEXT,22
category_within_source TEXT,23
source_domain TEXT,24
topic TEXT,25
topic_relevance_score TEXT,26
overall_sentiment_score REAL,27
overall_sentiment_label TEXT,28
`ticker` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,29
ticker_relevance_score DECIMAL(10, 6),30
ticker_sentiment_score DECIMAL(10, 6),31
ticker_sentiment_label TEXT,32
SORT KEY (`ticker`,`time_published` DESC),33
SHARD KEY `__SHARDKEY` (`ticker`,`time_published` DESC),34
KEY(ticker) USING HASH,35
KEY(authors) USING HASH,36
KEY(source) USING HASH,37
KEY(overall_sentiment_label) USING HASH,38
KEY(ticker_sentiment_label) USING HASH39
);40
41
CREATE ROWSTORE REFERENCE TABLE companyInfo (42
ticker VARCHAR(10) PRIMARY KEY,43
AssetType VARCHAR(50),44
Name VARCHAR(100),45
Description TEXT,46
CIK VARCHAR(10),47
Exchange VARCHAR(10),48
Currency VARCHAR(10),49
Country VARCHAR(50),50
Sector VARCHAR(50),51
Industry VARCHAR(250),52
Address VARCHAR(100),53
FiscalYearEnd VARCHAR(20),54
LatestQuarter DATE,55
MarketCapitalization BIGINT,56
EBITDA BIGINT,57
PERatio DECIMAL(10, 2),58
PEGRatio DECIMAL(10, 3),59
BookValue DECIMAL(10, 2),60
DividendPerShare DECIMAL(10, 2),61
DividendYield DECIMAL(10, 4),62
EPS DECIMAL(10, 2),63
RevenuePerShareTTM DECIMAL(10, 2),64
ProfitMargin DECIMAL(10, 4),65
OperatingMarginTTM DECIMAL(10, 4),66
ReturnOnAssetsTTM DECIMAL(10, 4),67
ReturnOnEquityTTM DECIMAL(10, 4),68
RevenueTTM BIGINT,69
GrossProfitTTM BIGINT,70
DilutedEPSTTM DECIMAL(10, 2),71
QuarterlyEarningsGrowthYOY DECIMAL(10, 3),72
QuarterlyRevenueGrowthYOY DECIMAL(10, 3),73
AnalystTargetPrice DECIMAL(10, 2),74
TrailingPE DECIMAL(10, 2),75
ForwardPE DECIMAL(10, 2),76
PriceToSalesRatioTTM DECIMAL(10, 3),77
PriceToBookRatio DECIMAL(10, 2),78
EVToRevenue DECIMAL(10, 3),79
EVToEBITDA DECIMAL(10, 2),80
Beta DECIMAL(10, 3),81
52WeekHigh DECIMAL(10, 2),82
52WeekLow DECIMAL(10, 2),83
50DayMovingAverage DECIMAL(10, 2),84
200DayMovingAverage DECIMAL(10, 2),85
SharesOutstanding BIGINT,86
DividendDate DATE,87
ExDividendDate DATE88
);89
90
CREATE TABLE `embeddings` (91
`id` bigint(11) NOT NULL AUTO_INCREMENT,92
`category` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,93
`question` longtext CHARACTER SET utf8 COLLATE utf8_general_ci,94
`question_embedding` longblob,95
`answer` longtext CHARACTER SET utf8 COLLATE utf8_general_ci,96
`answer_embedding` longblob,97
`created_at` datetime DEFAULT NULL,98
UNIQUE KEY `PRIMARY` (`id`) USING HASH,99
SHARD KEY `__SHARDKEY` (`id`),100
KEY `category` (`category`) USING HASH,101
SORT KEY `__UNORDERED` (`created_at` DESC)102
);
Out [2]:
In [3]:
1
%%sql2
SHOW TABLES;
Out [3]:
| Tables_in_llm_webinar |
|---|
| companyInfo |
| embeddings |
| newsSentiment |
| stockTable |
In [4]:
1
%pip install --quiet elevenlabs==0.2.27 openai==1.32.0 matplotlib scipy scikit-learn langchain==0.2.12 langchain-openai==0.1.20 langchain-community==0.2.11
In [5]:
1
import datetime2
import getpass3
import numpy as np4
import openai5
import requests6
import singlestoredb as s27
import time8
from datetime import datetime9
from datetime import timedelta10
from dateutil.relativedelta import relativedelta11
from langchain.sql_database import SQLDatabase12
from langchain_openai import OpenAI as LangchainOpenAI13
from langchain.agents.agent_toolkits import SQLDatabaseToolkit14
from langchain.agents import create_sql_agent
Set API keys
In [6]:
1
alpha_vantage_apikey = getpass.getpass("enter alphavantage apikey here")2
openai_apikey = getpass.getpass("enter openai apikey here")3
elevenlabs_apikey = getpass.getpass("enter elevenlabs apikey here")
In [7]:
1
from openai import OpenAI2
3
client = OpenAI(api_key=openai_apikey)4
5
def get_embeddings(inputs: list[str], model: str = 'text-embedding-ada-002') -> list[str]:6
"""Return list of embeddings."""7
return [x.embedding for x in client.embeddings.create(input=inputs, model=model).data]
Bring past two months of stock data
In [8]:
1
# set up connection to SingleStore and the ticker list2
s2_conn = s2.connect(connection_url)3
ticker_list = ['TSLA', 'AMZN', 'PLTR']
In [9]:
1
from datetime import datetime2
3
def get_past_months(num_months):4
today = datetime.today()5
months = []6
7
for months_ago in range(0, num_months):8
target_date = today - relativedelta(months=months_ago)9
months.append(target_date.strftime('%Y-%m'))10
11
return months12
13
num_months = 2 # Number of months14
year_month_list = get_past_months(num_months)15
print(year_month_list)16
17
# pull intraday data for each stock and write to SingleStore18
for ticker in ticker_list:19
print(ticker)20
data_list = []21
for year_month in year_month_list:22
print(year_month)23
24
intraday_price_url = "https://www.alphavantage.co/query?function=TIME_SERIES_INTRADAY&symbol={}&interval=5min&month={}&outputsize=full&apikey={}".format(ticker, year_month, alpha_vantage_apikey)25
r = requests.get(intraday_price_url)26
27
try:28
data = r.json()['Time Series (5min)']29
except:30
time.sleep(1) # required to not hit API limits31
continue32
33
for key in data:34
document = data[key]35
document['datetime'] = key36
document['ticker'] = ticker37
38
document['open'] = document['1. open']39
document['high'] = document['2. high']40
document['low'] = document['3. low']41
document['close'] = document['4. close']42
document['volume'] = document['5. volume']43
44
document['open'] = float(document['open'])45
document['high'] = float(document['high'])46
document['low'] = float(document['low'])47
document['close'] = float(document['close'])48
document['volume'] = int(document['volume'])49
50
51
del document['1. open']52
del document['2. high']53
del document['3. low']54
del document['4. close']55
del document['5. volume']56
57
data_list += [document]58
59
# Inside your loop, create the params dictionary with the correct values60
params = {61
'datetime': document['datetime'],62
'ticker': ticker,63
'open': document['open'],64
'high': document['high'],65
'low': document['low'],66
'close': document['close'],67
'volume': document['volume']68
}69
70
# Construct and execute the SQL statement71
table_name = 'stockTable'72
stmt = f"INSERT INTO {table_name} (created_at, ticker, open, high, low, close, volume) VALUES (%(datetime)s, %(ticker)s, %(open)s, %(high)s, %(low)s, %(close)s, %(volume)s)"73
74
with s2_conn.cursor() as cur:75
cur.execute(stmt, params)76
# time.sleep(1) # required to not hit API limits
In [10]:
1
%%sql2
select count(*) from stockTable
Out [10]:
| count(*) |
|---|
| 20629 |
Bring in Company data
In [11]:
1
def float_or_none(x):2
if x is None or x == 'None':3
return None4
return float(x)5
6
# pull intraday data for each stock and write to SingleStore7
for ticker in ticker_list:8
print(ticker)9
data_list = []10
# for year_month in year_month_list:11
12
company_overview = "https://www.alphavantage.co/query?function=OVERVIEW&symbol={}&outputsize=full&apikey={}".format(ticker, alpha_vantage_apikey)13
r = requests.get(company_overview)14
15
try:16
data = r.json()17
except:18
time.sleep(3) # required to not hit API limits19
continue20
21
if 'CIK' not in data:22
raise RuntimeError(str(data))23
24
data['CIK'] = int(data['CIK'])25
data['MarketCapitalization']= float_or_none(data['MarketCapitalization'])26
# Assuming data['EBITDA'] is a string containing 'None'27
ebitda_str = data['EBITDA']28
if ebitda_str.lower() == 'none':29
# Handle the case where EBITDA is 'None', for example, you can set it to 030
data['EBITDA'] = 0.031
else:32
# Convert the EBITDA string to a float33
data['EBITDA'] = float_or_none(ebitda_str)34
35
PERatio_flt = data['PERatio']36
if PERatio_flt.lower() == 'none':37
# Handle the case where EVToRevenue is '-'38
data['PERatio'] = 0.0 # You can use any default value that makes sense39
else:40
# Convert the EVToRevenue string to a float41
data['PERatio'] = float_or_none(PERatio_flt)42
43
data['PEGRatio']= float_or_none(data['PEGRatio'])44
data['BookValue']= float_or_none(data['BookValue'])45
data['DividendPerShare']= float_or_none(data['DividendPerShare'])46
data['DividendYield']= float_or_none(data['DividendYield'])47
data['EPS']= float_or_none(data['EPS'])48
data['RevenuePerShareTTM']= float_or_none(data['RevenuePerShareTTM'])49
data['ProfitMargin']= float_or_none(data['ProfitMargin'])50
data['OperatingMarginTTM']= float_or_none(data['OperatingMarginTTM'])51
data['ReturnOnAssetsTTM']= float_or_none(data['ReturnOnAssetsTTM'])52
data['ReturnOnEquityTTM']= float_or_none(data['ReturnOnEquityTTM'])53
data['RevenueTTM']= int(data['RevenueTTM'])54
data['GrossProfitTTM']= int(data['GrossProfitTTM'])55
data['DilutedEPSTTM']= float_or_none(data['DilutedEPSTTM'])56
data['QuarterlyEarningsGrowthYOY']= float_or_none(data['QuarterlyEarningsGrowthYOY'])57
data['QuarterlyRevenueGrowthYOY']= float_or_none(data['QuarterlyRevenueGrowthYOY'])58
data['AnalystTargetPrice']= float_or_none(data['AnalystTargetPrice'])59
# Assuming data['TrailingPE'] is a string containing '-'60
trailing_pe_str = data['TrailingPE']61
if trailing_pe_str == '-':62
# Handle the case where TrailingPE is '-'63
data['TrailingPE'] = 0.0 # You can use any default value that makes sense64
else:65
try:66
# Attempt to convert the TrailingPE string to a float67
data['TrailingPE'] = float_or_none(trailing_pe_str)68
except ValueError:69
# Handle the case where the conversion fails (e.g., if it contains invalid characters)70
data['TrailingPE'] = 0.0 # Set to a default value or handle as needed71
72
data['ForwardPE']= float_or_none(data['ForwardPE'])73
data['PriceToSalesRatioTTM']= float_or_none(data['PriceToSalesRatioTTM'])74
# Assuming data['EVToRevenue'] is a string containing '-'75
PriceToBookRatio_flt = data['PriceToBookRatio']76
if PriceToBookRatio_flt == '-':77
# Handle the case where EVToRevenue is '-'78
data['PriceToBookRatio'] = 0.0 # You can use any default value that makes sense79
else:80
# Convert the EVToRevenue string to a float81
data['PriceToBookRatio'] = float_or_none(PriceToBookRatio_flt)82
83
# Assuming data['EVToRevenue'] is a string containing '-'84
ev_to_revenue_str = data['EVToRevenue']85
if ev_to_revenue_str == '-':86
# Handle the case where EVToRevenue is '-'87
data['EVToRevenue'] = 0.0 # You can use any default value that makes sense88
else:89
# Convert the EVToRevenue string to a float90
data['EVToRevenue'] = float_or_none(ev_to_revenue_str)91
92
# data['EVToEBITDA']= float(data['EVToEBITDA'])93
# Assuming data['EVToRevenue'] is a string containing '-'94
ev_to_EBITDA_str = data['EVToEBITDA']95
if ev_to_revenue_str == '-':96
# Handle the case where EVToRevenue is '-'97
data['EVToEBITDA'] = 0.0 # You can use any default value that makes sense98
else:99
# Convert the EVToRevenue string to a float100
data['EVToEBITDA'] = float_or_none(ev_to_EBITDA_str)101
102
data['Beta']= float_or_none(data['Beta'])103
data['52WeekHigh']= float_or_none(data['52WeekHigh'])104
data['52WeekLow']= float_or_none(data['52WeekLow'])105
data['50DayMovingAverage']= float_or_none(data['50DayMovingAverage'])106
data['200DayMovingAverage']= float_or_none(data['200DayMovingAverage'])107
data['SharesOutstanding']= int(data['SharesOutstanding'])108
# description_embedding = [np.array(x, '<f4') for x in get_embeddings(data["Description"], model=model)]109
dividend_date_str = data['DividendDate']110
if dividend_date_str.lower() == 'none':111
# Handle the case where EBITDA is 'None', for example, you can set it to 0112
data['DividendDate'] = '9999-12-31'113
else:114
# Convert the EBITDA string to a float115
data['DividendDate'] = str(dividend_date_str)116
117
exdividend_date_str = data['ExDividendDate']118
if exdividend_date_str.lower() == 'none':119
# Handle the case where EBITDA is 'None', for example, you can set it to 0120
data['ExDividendDate'] = '9999-12-31'121
else:122
# Convert the EBITDA string to a float123
data['ExDividendDate'] = str(exdividend_date_str)124
125
data_list += [data]126
127
# Inside your loop, create the params dictionary with the correct values128
params = {129
"Symbol": data["Symbol"],130
"AssetType": data["AssetType"],131
"Name": data["Name"],132
"Description": data["Description"],133
"CIK": data["CIK"],134
"Exchange": data["Exchange"],135
"Currency": data["Currency"],136
"Country": data["Country"],137
"Sector": data["Sector"],138
"Industry": data["Industry"],139
"Address": data["Address"],140
"FiscalYearEnd": data["FiscalYearEnd"],141
"LatestQuarter": data["LatestQuarter"],142
"MarketCapitalization": data["MarketCapitalization"],143
"EBITDA": data["EBITDA"],144
"PERatio": data["PERatio"],145
"PEGRatio": data["PEGRatio"],146
"BookValue": data["BookValue"],147
"DividendPerShare": data["DividendPerShare"],148
"DividendYield": data["DividendYield"],149
"EPS": data["EPS"],150
"RevenuePerShareTTM": data["RevenuePerShareTTM"],151
"ProfitMargin": data["ProfitMargin"],152
"OperatingMarginTTM": data["OperatingMarginTTM"],153
"ReturnOnAssetsTTM": data["ReturnOnAssetsTTM"],154
"ReturnOnEquityTTM": data["ReturnOnEquityTTM"],155
"RevenueTTM": data["RevenueTTM"],156
"GrossProfitTTM": data["GrossProfitTTM"],157
"DilutedEPSTTM": data["DilutedEPSTTM"],158
"QuarterlyEarningsGrowthYOY": data["QuarterlyEarningsGrowthYOY"],159
"QuarterlyRevenueGrowthYOY": data["QuarterlyRevenueGrowthYOY"],160
"AnalystTargetPrice": data["AnalystTargetPrice"],161
"TrailingPE": data["TrailingPE"],162
"ForwardPE": data["ForwardPE"],163
"PriceToSalesRatioTTM": data["PriceToSalesRatioTTM"],164
"PriceToBookRatio": data["PriceToBookRatio"],165
"EVToRevenue": data["EVToRevenue"],166
"EVToEBITDA": data["EVToEBITDA"],167
"Beta": data["Beta"],168
"52WeekHigh": data["52WeekHigh"],169
"52WeekLow": data["52WeekLow"],170
"50DayMovingAverage": data["50DayMovingAverage"],171
"200DayMovingAverage": data["200DayMovingAverage"],172
"SharesOutstanding": data["SharesOutstanding"],173
"DividendDate": data["DividendDate"],174
"ExDividendDate": data["ExDividendDate"]175
}176
177
# Construct and execute the SQL statement178
table_name = 'companyInfo'179
stmt = f"INSERT INTO {table_name} (ticker, AssetType, Name, Description, CIK, Exchange, Currency, Country, Sector, Industry, Address, FiscalYearEnd, LatestQuarter, MarketCapitalization, EBITDA, PERatio, PEGRatio, BookValue, DividendPerShare, DividendYield, EPS, RevenuePerShareTTM, ProfitMargin, OperatingMarginTTM, ReturnOnAssetsTTM, ReturnOnEquityTTM, RevenueTTM, GrossProfitTTM, DilutedEPSTTM, QuarterlyEarningsGrowthYOY, QuarterlyRevenueGrowthYOY, AnalystTargetPrice, TrailingPE, ForwardPE, PriceToSalesRatioTTM, PriceToBookRatio, EVToRevenue, EVToEBITDA, Beta, 52WeekHigh, 52WeekLow, 50DayMovingAverage, 200DayMovingAverage, SharesOutstanding, DividendDate, ExDividendDate) VALUES (%(Symbol)s, %(AssetType)s, %(Name)s, %(Description)s, %(CIK)s, %(Exchange)s, %(Currency)s, %(Country)s, %(Sector)s, %(Industry)s, %(Address)s, %(FiscalYearEnd)s, %(LatestQuarter)s, %(MarketCapitalization)s, %(EBITDA)s, %(PERatio)s, %(PEGRatio)s, %(BookValue)s, %(DividendPerShare)s, %(DividendYield)s, %(EPS)s, %(RevenuePerShareTTM)s, %(ProfitMargin)s, %(OperatingMarginTTM)s, %(ReturnOnAssetsTTM)s, %(ReturnOnEquityTTM)s, %(RevenueTTM)s, %(GrossProfitTTM)s, %(DilutedEPSTTM)s, %(QuarterlyEarningsGrowthYOY)s, %(QuarterlyRevenueGrowthYOY)s, %(AnalystTargetPrice)s, %(TrailingPE)s, %(ForwardPE)s, %(PriceToSalesRatioTTM)s, %(PriceToBookRatio)s, %(EVToRevenue)s, %(EVToEBITDA)s, %(Beta)s, %(52WeekHigh)s, %(52WeekLow)s, %(50DayMovingAverage)s, %(200DayMovingAverage)s, %(SharesOutstanding)s, %(DividendDate)s, %(ExDividendDate)s)"180
181
# Replace table_name with the actual table name you're using.182
with s2_conn.cursor() as cur:183
cur.execute(stmt, params)
In [12]:
1
%%sql2
select * from companyInfo limit 1
Out [12]:
| ticker | AssetType | Name | Description | CIK | Exchange | Currency | Country | Sector | Industry | Address | FiscalYearEnd | LatestQuarter | MarketCapitalization | EBITDA | PERatio | PEGRatio | BookValue | DividendPerShare | DividendYield | EPS | RevenuePerShareTTM | ProfitMargin | OperatingMarginTTM | ReturnOnAssetsTTM | ReturnOnEquityTTM | RevenueTTM | GrossProfitTTM | DilutedEPSTTM | QuarterlyEarningsGrowthYOY | QuarterlyRevenueGrowthYOY | AnalystTargetPrice | TrailingPE | ForwardPE | PriceToSalesRatioTTM | PriceToBookRatio | EVToRevenue | EVToEBITDA | Beta | 52WeekHigh | 52WeekLow | 50DayMovingAverage | 200DayMovingAverage | SharesOutstanding | DividendDate | ExDividendDate |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AMZN | Common Stock | Amazon.com Inc | Amazon.com, Inc. is an American multinational technology company which focuses on e-commerce, cloud computing, digital streaming, and artificial intelligence. It is one of the Big Five companies in the U.S. information technology industry, along with Google, Apple, Microsoft, and Facebook. The company has been referred to as one of the most influential economic and cultural forces in the world, as well as the world's most valuable brand. | 1018724 | NASDAQ | USD | USA | TRADE & SERVICES | RETAIL-CATALOG & MAIL-ORDER HOUSES | 410 TERRY AVENUE NORTH, SEATTLE, WA, US | December | 2024-06-30 | 1877452915000 | 104049000000 | 42.69 | 2.161 | 22.54 | None | None | 4.19 | 58.22 | 0.0735 | 0.0992 | 0.0658 | 0.2190 | 604333998000 | 225152000000 | 4.19 | 0.938 | 0.101 | 197.21 | 42.69 | 38.46 | 3.107 | 7.91 | 3.168 | 17.97 | 1.155 | 201.20 | 118.35 | 184.08 | 171.02 | 10495600000 | 9999-12-31 | 9999-12-31 |
Bring in news sentiment
In [13]:
1
import datetime2
3
# pull intraday data for each stock and write to Mongo4
for ticker in ticker_list:5
print(ticker)6
data_list = []7
8
for i in year_month_list:9
date_object = datetime.datetime.strptime(i, '%Y-%m')10
print(date_object)11
output_date = date_object.strftime('%Y%m%d') + "T0000"12
13
# Get the next month from the 'date_object'14
previous_month_date = date_object + relativedelta(months=-1)15
previous_month_date = previous_month_date.strftime('%Y%m%d') + "T0000"16
17
# Update 'date_object' for the next iteration18
date_object = previous_month_date19
20
# replace the "demo" apikey below with your own key from https://www.alphavantage.co/support/#api-key21
news_and_sentiment = 'https://www.alphavantage.co/query?function=NEWS_SENTIMENT&tickers={}&time_from={}&time_to={}&limit=1000&outputsize=full&apikey={}'.format(ticker, previous_month_date, output_date, alpha_vantage_apikey)22
r = requests.get(news_and_sentiment)23
24
try:25
data = r.json()26
data = data["feed"]27
except:28
time.sleep(2) # required to not hit API limits29
continue30
31
for item in data:32
item['title'] = str(item['title'])33
item['url'] = str(item['url'])34
item['time_published'] = datetime.datetime.strptime(str(item['time_published']), "%Y%m%dT%H%M%S").strftime("%Y-%m-%d %H:%M:%S")35
36
if item['authors']:37
# Check if the 'authors' list is not empty38
authors_str = str(item['authors'][0])39
else:40
# Handle the case where 'authors' is empty41
authors_str = "No authors available"42
43
item['authors'] = authors_str44
45
item['summary'] = str(item['summary'])46
item['banner_image'] = str(item['banner_image'])47
item['source'] = str(item['source'])48
item['category_within_source'] = str(item['category_within_source'])49
item['source_domain'] = str(item['source_domain'])50
item['topic'] = str(item['topics'][0]["topic"])51
item['topic_relevance_score'] = float(item['topics'][0]['relevance_score'])52
item['overall_sentiment_score'] = float(item['overall_sentiment_score'])53
item['overall_sentiment_label'] = str(item['overall_sentiment_label'])54
item['ticker'] = str(item['ticker_sentiment'][0]['ticker'])55
item['ticker_relevance_score'] = float(item['ticker_sentiment'][0]['relevance_score'])56
item['ticker_sentiment_score'] = float(item['ticker_sentiment'][0]['ticker_sentiment_score'])57
item['ticker_sentiment_label'] = str(item['ticker_sentiment'][0]['ticker_sentiment_label'])58
59
params= {60
"title": item["title"],61
"url": item["url"],62
"time_published": item["time_published"],63
"authors": item["authors"],64
"summary": item["summary"],65
"banner_image": item["banner_image"],66
"source": item["source"],67
"category_within_source": item["category_within_source"],68
"source_domain": item["source_domain"],69
"topic": item["topic"],70
"topic_relevance_score": item['topic_relevance_score'],71
'overall_sentiment_score': item['overall_sentiment_score'],72
'overall_sentiment_label': item['overall_sentiment_label'],73
'ticker': item['ticker'],74
'ticker_relevance_score': item['ticker_relevance_score'],75
'ticker_sentiment_score': item['ticker_sentiment_score'],76
'ticker_sentiment_label': item['ticker_sentiment_label']77
}78
#print(params)79
80
# Construct and execute the SQL statement81
table_name = 'newsSentiment'82
stmt = f"INSERT INTO {table_name} (title, url, time_published, authors, summary, banner_image, source, category_within_source, source_domain, topic, topic_relevance_score, overall_sentiment_score, overall_sentiment_label, ticker, ticker_relevance_score, ticker_sentiment_score, ticker_sentiment_label) VALUES (%(title)s, %(url)s, %(time_published)s, %(authors)s, %(summary)s, %(banner_image)s, %(source)s, %(category_within_source)s, %(source_domain)s, %(topic)s, %(topic_relevance_score)s, %(overall_sentiment_score)s, %(overall_sentiment_label)s, %(ticker)s, %(ticker_relevance_score)s, %(ticker_sentiment_score)s, %(ticker_sentiment_label)s)"83
84
# Replace table_name with the actual table name you're using.85
86
with s2_conn.cursor() as cur:87
cur.execute(stmt, params)
In [14]:
1
%%sql2
SELECT count(*) Rows_in_newsSentiment FROM newsSentiment
Out [14]:
| Rows_in_newsSentiment |
|---|
| 2359 |
In [15]:
1
os.environ["OPENAI_API_KEY"] = openai_apikey2
embedding_model = 'text-embedding-ada-002'3
gpt_model = 'gpt-3.5-turbo-16k'4
5
# Create the agent executor6
db = SQLDatabase.from_uri(connection_url, include_tables=['embeddings', 'companyInfo', 'newsSentiment', 'stockTable'], sample_rows_in_table_info=2)7
llm = LangchainOpenAI(openai_api_key=os.environ["OPENAI_API_KEY"], temperature=0, verbose=True)8
toolkit = SQLDatabaseToolkit(db=db, llm=llm)9
10
agent_executor = create_sql_agent(11
llm=LangchainOpenAI(temperature=0),12
toolkit=toolkit,13
verbose=True,14
prefix= '''15
You are an agent designed to interact with a SQL database called SingleStore. This sometimes has Shard and Sort keys in the table schemas, which you can ignore.16
\nGiven an input question, create a syntactically correct MySQL query to run, then look at the results of the query and return the answer.17
\n If you are asked about similarity questions, you should use the DOT_PRODUCT function.18
19
\nHere are a few examples of how to use the DOT_PRODUCT function:20
\nExample 1:21
Q: how similar are the questions and answers?22
A: The query used to find this is:23
24
select question, answer, dot_product(question_embedding, answer_embedding) as similarity from embeddings;25
26
\nExample 2:27
Q: What are the most similar questions in the embeddings table, not including itself?28
A: The query used to find this answer is:29
30
SELECT q1.question as question1, q2.question as question2, DOT_PRODUCT(q1.question_embedding, q2.question_embedding) :> float as score31
FROM embeddings q1, embeddings q232
WHERE question1 != question233
ORDER BY score DESC LIMIT 5;34
35
\nExample 3:36
Q: In the embeddings table, which rows are from the chatbot?37
A: The query used to find this answer is:38
39
SELECT category, question, answer FROM embeddings40
WHERE category = 'chatbot';41
42
\nIf you are asked to describe the database, you should run the query SHOW TABLES43
\nUnless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.44
\n The question embeddings and answer embeddings are very long, so do not show them unless specifically asked to.45
\nYou can order the results by a relevant column to return the most interesting examples in the database.46
\nNever query for all the columns from a specific table, only ask for the relevant columns given the question.47
\nYou have access to tools for interacting with the database.\nOnly use the below tools.48
Only use the information returned by the below tools to construct your final answer.49
\nYou MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again up to 3 times.50
\n\nDO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.51
\n\nIf the question does not seem related to the database, just return "I don\'t know" as the answer.\n,52
53
''',54
format_instructions='''Use the following format:\n55
\nQuestion: the input question you must answer56
\nThought: you should always think about what to do57
\nAction: the action to take, should be one of [{tool_names}]58
\nAction Input: the input to the action59
\nObservation: the result of the action60
\nThought: I now know the final answer61
\nFinal Answer: the final answer to the original input question62
\nSQL Query used to get the Answer: the final sql query used for the final answer'63
''',64
top_k=3,65
max_iterations=566
)
Create function that processes user question with a check in Semantic Cache Layer
In [16]:
1
table_name = 'embeddings'2
similarity_threshold = .973
4
def process_user_question(question):5
print(f'\nQuestion asked: {question}')6
category = 'chatbot'7
8
# Get vector embedding from the original question and calculate the elapsed time9
start_time = time.time()10
question_embedding= [np.array(x, '<f4') for x in get_embeddings([question], model=embedding_model)]11
elapsed_time = (time.time() - start_time) * 100012
print(f"Execution time for getting the question embedding: {elapsed_time:.2f} milliseconds")13
14
params = {15
'question_embedding': question_embedding,16
}17
18
# Check if embedding is similar to existing questions19
# If semantic score < similarity_threshold, then run the agent executor20
# Calculate elapsed time for this step21
22
stmt = f'select question, answer, dot_product( %(question_embedding)s, question_embedding) :> float as score from embeddings where category="chatbot" order by score desc limit 1;'23
24
25
with s2_conn.cursor() as cur:26
start_time = time.time()27
cur.execute(stmt, params)28
row = cur.fetchone()29
elapsed_time = (time.time() - start_time) * 100030
print(f"Execution time for checking existing questions: {elapsed_time:.2f} milliseconds")31
32
try:33
question2, answer, score = row34
print(f"\nClosest Matching row:\nQuestion: {question2}\nAnswer: {answer}\nSimilarity Score: {score}")35
36
if score > similarity_threshold:37
print('Action to take: Using existing answer')38
return answer39
40
else:41
print('Action to take: Running agent_executor')42
start_time = time.time()43
answer2 = agent_executor.run(question)44
elapsed_time = (time.time() - start_time) * 100045
print(f"agent_executor execution time: {elapsed_time:.2f} milliseconds")46
47
# Get current time48
created_at = datetime.now().strftime("%Y-%m-%d %H:%M:%S")49
50
# Get the answer embedding and calculate the elapsed time51
start_time = time.time()52
answer_embedding = [np.array(x, '<f4') for x in get_embeddings([answer2], model=embedding_model)]53
elapsed_time = (time.time() - start_time) * 100054
print(f"Answer embeddings execution time: {elapsed_time:.2f} milliseconds")55
56
params = {'category': category, 'question': question,57
'question_embedding': question_embedding,58
'answer': answer2, 'answer_embedding': answer_embedding,59
'created_at': created_at}60
61
# Send params details as a row into the SingleStoreDB embeddings table and calculate the elapsed time62
stmt = f"INSERT INTO {table_name} (category, question, question_embedding, answer, answer_embedding, created_at) VALUES (%(category)s, \n%(question)s, \n%(question_embedding)s, \n%(answer)s, \n%(answer_embedding)s, \n%(created_at)s)"63
start_time = time.time()64
65
with s2_conn.cursor() as cur:66
cur.execute(stmt, params)67
68
elapsed_time = (time.time() - start_time) * 100069
print(f"Insert to SingleStore execution time: {elapsed_time:.2f} milliseconds")70
71
return answer272
73
# Handle known exceptions then run as normal74
except:75
print('No existing rows. Running agent_executor')76
start_time = time.time()77
answer2 = agent_executor.run(question)78
elapsed_time = (time.time() - start_time) * 100079
print(f"agent_executor execution time: {elapsed_time:.2f} milliseconds")80
81
created_at = datetime.now().strftime("%Y-%m-%d %H:%M:%S")82
83
# Record the start time84
start_time = time.time()85
86
answer_embedding = [np.array(x, '<f4') for x in get_embeddings([answer2], model=embedding_model)]87
88
# Calculate the elapsed time89
elapsed_time = (time.time() - start_time) * 100090
print(f"Answer embeddings execution time: {elapsed_time:.2f} milliseconds")91
92
params = {'category': category, 'question': question,93
'question_embedding': question_embedding,94
'answer': answer2, 'answer_embedding': answer_embedding,95
'created_at': created_at}96
97
# Send to SingleStoreDB98
stmt = f"INSERT INTO {table_name} (category, question, question_embedding, answer, answer_embedding, created_at) VALUES (%(category)s, \n%(question)s, \n%(question_embedding)s, \n%(answer)s, \n%(answer_embedding)s, \n%(created_at)s)"99
100
# Record the start time101
start_time = time.time()102
103
with s2_conn.cursor() as cur:104
cur.execute(stmt, params)105
106
# Calculate the elapsed time107
elapsed_time = (time.time() - start_time) * 1000108
print(f"Insert to SingleStore execution time: {elapsed_time:.2f} milliseconds")109
110
return answer2
Test on two similar questions
In [17]:
1
from datetime import datetime2
# Two similar questions3
question_1 = "describe the database"4
question_2 = "describe database"
In [18]:
1
# Question: describe the database2
answer = process_user_question(question_1)3
print(f'The answer is: {answer}')
In [19]:
1
%%sql2
select id, category, question, answer from embeddings limit 1
Out [19]:
| id | category | question | answer |
|---|---|---|---|
| 1125899906842625 | chatbot | describe the database | The database contains information on various companies, including their ticker, asset type, name, description, CIK, exchange, currency, country, sector, industry, address, fiscal year end, latest quarter, market capitalization, EBITDA, P/E ratio, PEG ratio, book value, dividend per share, dividend yield, EPS, revenue per share, profit margin, operating margin, return on assets, return on equity, revenue, gross profit, diluted EPS, quarterly earnings growth, quarterly revenue growth, analyst target price, trailing P/E, forward P/E, price to sales ratio, price to book ratio, EV to revenue, EV to EBITDA, beta, 52-week high, 52-week low, 50-day moving average, 200-day moving average, shares outstanding, dividend date, and ex-dividend date. SQL Query used to get the Answer: SELECT * FROM companyInfo; |
In [20]:
1
# Question: describe database2
answer = process_user_question(question_2)3
print(f'The answer is: {answer}')
Select a voice
In [21]:
1
from elevenlabs import generate, stream, voices2
from elevenlabs import set_api_key3
from IPython.display import Audio4
from IPython.display import display5
import requests
In [22]:
1
voices = voices()2
voices[0]
Out [22]:
Voice(voice_id='EXAVITQu4vr4xnSDxMaL', name='Sarah', category='premade', description=None, labels={'description': 'soft', 'accent': 'american', 'age': 'young', 'gender': 'female', 'use_case': 'news'}, samples=None, design=None, preview_url='https://storage.googleapis.com/eleven-public-prod/premade/voices/EXAVITQu4vr4xnSDxMaL/01a3e33c-6e99-4ee7-8543-ff2216a32186.mp3', settings=None)In [23]:
1
CHUNK_SIZE = 10242
url = "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM/stream"3
4
headers = {5
"Accept": "audio/mpeg",6
"Content-Type": "application/json",7
"xi-api-key": elevenlabs_apikey8
}9
10
data = {11
"text": answer,12
"model_id": "eleven_monolingual_v1",13
"voice_settings": {14
"stability": 0.5,15
"similarity_boost": 0.516
}17
}18
19
response = requests.post(url, json=data, headers=headers, stream=True)20
21
# create an audio file22
with open('output.mp3', 'wb') as f:23
for chunk in response.iter_content(chunk_size=CHUNK_SIZE):24
if chunk:25
f.write(chunk)
In [24]:
1
!ls
In [25]:
1
audio_file = 'output.mp3'2
3
audio = Audio(filename=audio_file, autoplay =True)4
display(audio)
Out [25]:
Transcribe the audio file
In [26]:
1
openai.api_key = openai_apikey2
audio_file= open("output.mp3", "rb")3
transcript = client.audio.transcriptions.create(model="whisper-1", file=audio_file)4
print(transcript.text)
In [27]:
1
# Most recent news article for TSLA2
question_3 = """What is the most recent news article for Amazon where the topic_relevance_score is greater than 90%?3
Include the url, time published and banner image."""4
answer = process_user_question(question_3)5
print(f'The answer is: {answer}')
In [28]:
1
%%sql2
SELECT title, url, time_published, banner_image FROM newsSentiment WHERE ticker = 'AMZN' AND topic_relevance_score > 0.9 ORDER BY time_published DESC LIMIT 3
Out [28]:
| title | url | time_published | banner_image |
|---|---|---|---|
| Why Amazon Stock Popped on Wednesday | https://www.fool.com/investing/2024/07/31/why-amazon-stock-popped-on-wednesday/ | 2024-07-31 17:47:27 | https://g.foolcdn.com/editorial/images/785374/amazon-flex-driver-delivering-package-to-door-step.png |
| Will NBA Rights Move The Needle For Amazon Prime Video Subscribers? Poll Shows Small Impact From New Deal - Amazon.com ( NASDAQ:AMZN ) | https://www.benzinga.com/general/entertainment/24/07/40047859/will-nba-rights-move-the-needle-for-amazon-prime-video-subscribers-benzinga-poll-shows-smal | 2024-07-30 18:26:38 | https://cdn.benzinga.com/files/images/story/2024/07/30/amazon-prime-shutter.jpeg?width=1200&height=800&fit=crop |
| Unlocking Q2 Potential of Amazon ( AMZN ) : Exploring Wall Street Estimates for Key Metrics | https://www.zacks.com/stock/news/2310726/unlocking-q2-potential-of-amazon-amzn-exploring-wall-street-estimates-for-key-metrics | 2024-07-29 13:16:08 | https://staticx-tuner.zacks.com/images/default_article_images/default212.jpg |
Load the image
In [29]:
1
import matplotlib.pyplot as plt2
import matplotlib.image as mpimg3
from io import BytesIO4
banner_image_url = "https://staticx-tuner.zacks.com/images/default_article_images/default341.jpg"5
response = requests.get(banner_image_url)6
7
if response.status_code == 200:8
img = mpimg.imread(BytesIO(response.content), format='JPG')9
imgplot = plt.imshow(img)10
plt.show()11
else:12
print(f"Failed to retrieve the image. Status code: {response.status_code}")
Out [29]:
<Figure size 640x480 with 1 Axes>Set up the huggingface transformer
In [30]:
1
transformers_version = "v4.29.0" #@param ["main", "v4.29.0"] {allow-input: true}2
3
print(f"Setting up everything with transformers version {transformers_version}")4
5
%pip install --quiet huggingface_hub>=0.14.1 git+https://github.com/huggingface/transformers@$transformers_version pyarrow==12.0.1 diffusers==0.30.0 accelerate==0.33.0 datasets==2.15.0 torch==2.1.0 soundfile==0.12.1 sentencepiece==0.2.0 opencv-contrib-python-headless==4.8.1.78
In [31]:
1
import IPython2
import soundfile as sf3
4
def play_audio(audio):5
sf.write("speech_converted.wav", audio.numpy(), samplerate=16000)6
return IPython.display.Audio("speech_converted.wav")7
8
from huggingface_hub import notebook_login9
notebook_login()
Out [31]:
VBox(children=(HTML(value='<center> <img\nsrc=https://huggingface.co/front/assets/huggingface_logo-noborder.sv…In [32]:
1
agent_name = "StarCoder (HF Token)" #@param ["StarCoder (HF Token)", "OpenAssistant (HF Token)", "OpenAI (API Key)"]2
3
if agent_name == "StarCoder (HF Token)":4
from transformers.tools import HfAgent5
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")6
print("StarCoder is initialized 💪")7
8
elif agent_name == "OpenAssistant (HF Token)":9
from transformers.tools import HfAgent10
agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")11
print("OpenAssistant is initialized 💪")12
13
elif agent_name == "OpenAI (API Key)":14
from transformers.tools import OpenAiAgent15
pswd = openai_apikey16
agent = OpenAiAgent(model="gpt-3.5-turbo", api_key=pswd)17
print("OpenAI is initialized 💪")
Out [32]:
tool_config.json: 0%| | 0.00/331 [00:00<?, ?B/s]In [33]:
1
caption = agent.run("Can you caption the `image`?", image=img)
In [34]:
1
data = {2
"text": caption,3
"model_id": "eleven_monolingual_v1",4
"voice_settings": {5
"stability": 0.5,6
"similarity_boost": 0.57
}8
}9
10
response = requests.post(url, json=data, headers=headers)11
with open('output.mp3', 'wb') as f:12
for chunk in response.iter_content(chunk_size=CHUNK_SIZE):13
if chunk:14
f.write(chunk)15
16
audio_file = 'output.mp3'17
18
audio = Audio(filename=audio_file, autoplay =True)19
display(audio)
Out [34]:
Handle transactional and analytical queries with your vector data
no need to export data out of SingleStore to another vector db
Scan vectors fast with exact nearest neighbor. (DOT_PRODUCT, EUCLIDEAN_DISTANCE, and VECTOR_SUB are high-perf functions using single-instruction-multiple-data (SIMD) processor instructions)
Ability to stream data directly into SingleStore
Use SingleStore as Semantic Cache Layer leveraging the Plancache. No need for a cache layer.
Easily scale the workspace for your workload
handle reads and writes in parallel
Use of external functions.
Reset Demo
In [35]:
1
%%sql2
DROP DATABASE llm_webinar;
Out [35]:
Details
About this Template
Using OpenAI to build an app that can take images, audio, and text data to generate output
This Notebook can be run in Standard and Enterprise deployments.
Tags
advancedopenaigenaivectordb
License
This Notebook has been released under the Apache 2.0 open source license.
See Notebook in action
Launch this notebook in SingleStore and start executing queries instantly.