SingleStore Notebooks
New



Unified Data Analysis: SQL & NoSQL on a Single Database with Kai
Notebook
Unified Data Analysis: SQL & NoSQL on a Single Database with Kai
What you will learn in this notebook:
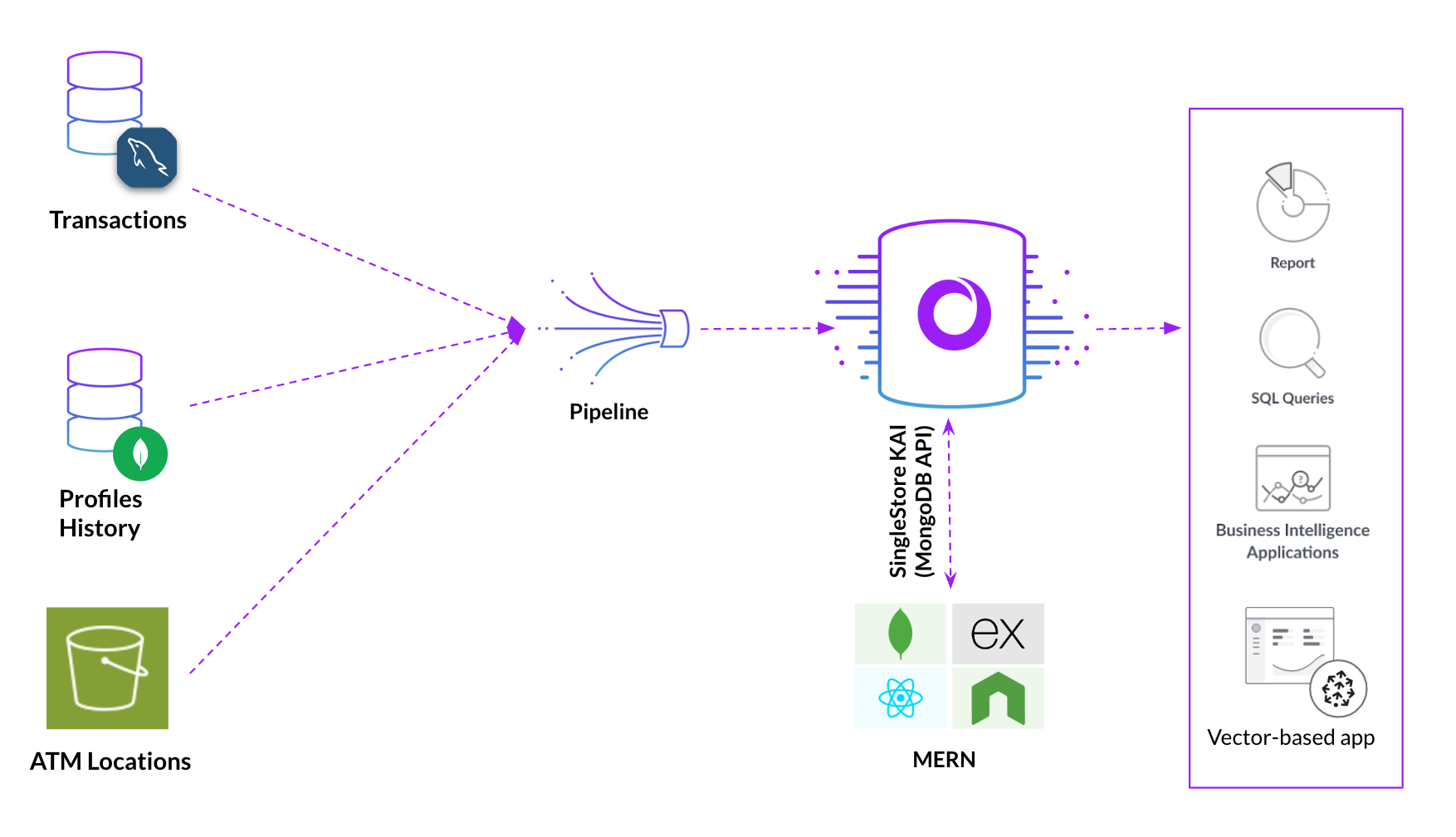
In this notebook we ingest data from from different sources like MySQL, MongoDB and S3 and perform efficient analysis using both NoSQL and SQL on multimodal data (tabular and JSON).
Highlights
Setup CDC from MongoDB and MySQL in easy steps. Replicate data in real-time and ensure upto date information for analytics, eliminating the need for complex tooling for data movement
Analyze data using both NoSQL and relational approaches, depending on your specific needs. Developers and data analytics who are familiar with different programming approaches like MongoDB query language and SQL can work together on the same database. Perform familiar SQL queries on your NoSQL data!
Ready to unlock real-time analytics and unified data access? Let's start!
In [1]:
1!pip install pymongo prettytable matplotlib --quiet
Create database for importing data from different sources
This example gets banking data from three different sources: ATM locations from S3, transaction data from MySQL and user profile details from MongoDB databases. Joins data from different sources to generate rich insights about the transactional activity across user profile and locations across the globe
In [2]:
1%%sql2DROP DATABASE IF EXISTS BankingAnalytics;3CREATE DATABASE BankingAnalytics;
Action Required
Make sure to select 'BankingAnalytics' database from the drop-down menu at the top of this notebook. It updates the connection_url to connect to that database.
Setup CDC from MySQL
SingleStore allows you to ingest the data from mysql using pipelines
In this step, we create a link from MySQL instance and start the pipelines for the CDC
In [3]:
1%%sql2CREATE LINK mysqllink AS MYSQL3CONFIG '{4 "database.hostname": "3.132.226.181",5 "database.exclude.list": "mysql,performance_schema",6 "table.include.list": "DomainAnalytics.transactions",7 "database.port": 3306,8 "database.ssl.mode":"required"9 }'10CREDENTIALS '{11 "database.password": "Password@123",12 "database.user": "repl_user"13 }';
In [4]:
1%%sql2CREATE TABLES AS INFER PIPELINE AS LOAD DATA LINK mysqllink "*" FORMAT AVRO;
In [5]:
1%%sql2START ALL PIPELINES;
Migrate the data from S3 storage to SingleStore using Pipelines
This steps loads data from S3, this requires the tables to be defined beforehand
In [6]:
1%%sql2CREATE TABLE IF NOT EXISTS atm_locations (3 id INT PRIMARY KEY,4 name VARCHAR(255),5 address VARCHAR(255),6 city VARCHAR(255),7 country VARCHAR(255),8 latitude DECIMAL(9, 6),9 longitude DECIMAL(9, 6)10);
In [7]:
1%%sql2CREATE PIPELINE atmlocations AS3LOAD DATA S3 's3://ocbfinalpoc1/data'4CONFIG '{"region":"ap-southeast-1"}'5SKIP DUPLICATE KEY ERRORS6INTO TABLE atm_locations;
In [8]:
1%%sql2START PIPELINE atmlocations
Setup CDC from MongoDB to SingleStore
Now we setup CDC from MongoDB to replicate the data SingleStore
The collections to be replicated are specified as a comma separated or in a wildcard format in "collection.include.list"
In [9]:
1%%sql2CREATE LINK mongo AS MONGODB3CONFIG '{4 "mongodb.hosts":"ac-t7n47to-shard-00-00.tfutgo0.mongodb.net:27017,ac-t7n47to-shard-00-01.tfutgo0.mongodb.net:27017,ac-t7n47to-shard-00-02.tfutgo0.mongodb.net:27017",5 "collection.include.list": "bank.*",6 "mongodb.ssl.enabled":"true",7 "mongodb.authsource":"admin",8 "mongodb.members.auto.discover": "true"9 }'10CREDENTIALS '{11 "mongodb.user":"mongo_sample_reader",12 "mongodb.password":"SingleStoreRocks27017"13 }';
In [10]:
1%%sql2CREATE TABLES AS INFER PIPELINE AS LOAD DATA LINK mongo '*' FORMAT AVRO;
In [11]:
1%%sql2SHOW PIPELINES
In [12]:
1%%sql2START ALL PIPELINES
Check for records in tables
Data from MySQL
In [13]:
1%%sql2SELECT COUNT(*) FROM transactions
In [14]:
1%%sql2SELECT * FROM transactions WHERE transaction_type LIKE '%Deposit%' LIMIT 1;
Data from S3
In [15]:
1%%sql2SELECT COUNT(*) FROM atm_locations
In [16]:
1%%sql2SELECT * FROM atm_locations LIMIT 1;
Data from MongoDB
In [17]:
1%%sql2SELECT _id:>JSON, _more:>JSON FROM profile LIMIT 1;
In [18]:
1%%sql2 3SELECT _id:>JSON, _more:>JSON FROM history LIMIT 1;
Join tables from different sources using SQL queries
SQL Query 1: View Users details, their associated ATMs
In [19]:
1%%sql2SELECT3 p._more::$full_name AS NameOfPerson,4 p._more::$email AS Email,5 a.id,6 a.name AS ATMName,7 a.city,8 a.country9FROM10 profile p,11 atm_locations a12WHERE13 p._more::$account_id = a.id14LIMIT 10;
SQL Query 2: View Users details, their associated ATMs and transaction details
In [20]:
1%%sql2SELECT3 p._more::$full_name AS NameOfPerson,4 p._more::$email AS Email,5 a.id,6 a.name AS ATMName,7 a.city,8 t.transaction_id,9 t.transaction_date,10 t.amount,11 t.transaction_type,12 t.description13FROM14 profile p15JOIN16 atm_locations a ON p._more::$account_id = a.id17LEFT JOIN18 transactions t ON p._more::$account_id = t.account_id19LIMIT 10;
Run queries in Mongo Query Language using Kai
In [21]:
1from pymongo import MongoClient2import pprint3from prettytable import PrettyTable4 5client = MongoClient(connection_url_kai)6 7# Get the profile collection8db = client['BankingAnalytics']9profile_coll = db['profile']10 11for profile in profile_coll.find().limit(1):12 pprint.pprint(profile)
In [22]:
1pipeline = [2 {3 "$lookup": {4 "from": "profile",5 "localField": "account_id",6 "foreignField": "account_id",7 "as": "profile_data"8 }9 },10 {11 "$limit": 512 },13 {14 "$group": {15 "_id": "$_id",16 "history_data": {"$first": "$$ROOT"},17 "profile_data": {"$first": {"$arrayElemAt": ["$profile_data", 0]}}18 }19 },20 {21 "$project": {22 "_id": "$history_data._id",23 "account_id": "$history_data.account_id",24 "history_data": "$history_data",25 "profile_data": "$profile_data"26 }27 }28]29 30# Execute the aggregation pipeline31result = list(db.history.aggregate(pipeline))32 33# Print the result in a tabular format34table = PrettyTable(["Account ID", "Full Name", "Date of Birth", "City", "State", "Country", "Postal Code", "Phone Number", "Email"])35for doc in result:36 profile_data = doc["profile_data"]37 table.add_row([38 doc["account_id"],39 profile_data.get("full_name", ""),40 profile_data.get("date_of_birth", ""),41 profile_data.get("city", ""),42 profile_data.get("state", ""),43 profile_data.get("country", ""),44 profile_data.get("postal_code", ""),45 profile_data.get("phone_number", ""),46 profile_data.get("email", "")47 ])48 49print(table)
In [23]:
1# Get the state with highest number of customers2from bson.son import SON3 4pipeline = [5 {"$group": {"_id": "$state", "count": {"$sum": 1}}},6 {"$sort": SON([("count", -1), ("_id", -1)])},7 {"$limit": 5}8]9 10pprint.pprint(list(profile_coll.aggregate(pipeline)))
In [24]:
1import matplotlib.pyplot as plt2 3data = list(profile_coll.aggregate(pipeline))4 5print(data)6 7country,count = [dcts['_id'] for dcts in data],[dcts['count'] for dcts in data]8 9plt.bar(country,count)10plt.plot()
With SingleStore Kai you can power analytics on SQL and NoSQL data using the API of your choice
Details
About this Template
Perform both SQL and NoSQL queries on multi-modal relational and JSON data
This Notebook can be run in Standard and Enterprise deployments.
Tags
cdcmongosqlnosqlkai
See Notebook in action
Launch this notebook in SingleStore and start executing queries instantly.
License
This Notebook has been released under the Apache 2.0 open source license.